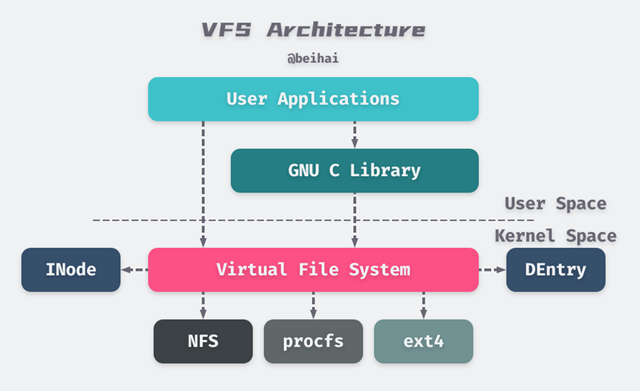
Linux 支持多种文件系统,为了让应用程序能够对所有系统不加区分的操作,Linux 提供了一个抽象层,这个抽象层介于应用程序和具体的文件系统之间,就像一个开关一样将用户请求转换到具体文件系统系统去,让具体文件系统去实现对应的操作,最后再将结果返回给用户。所以 VFS (Virtual File System/Virtual Filesystem Switch) 就叫做虚拟文件系统开关,确切地也可称之为虚拟文件系统转换,不过我认为开关比较形象。
另一方面,VFS 是 Linux 所有子系统中的一员,还有其他子系统如 IPC, SCHED, MM, NET 等,它们只会和 VFS 打交道,而不会去针对具体的文件系统直接操作。也就是说不仅用户空间接受 VFS 服务,内核空间也接受 VFS 服务。
磁盘结构
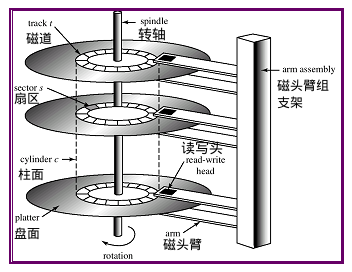
硬盘首先在逻辑上被划分为磁道、柱面以及扇区。磁盘在格式化时被划分成许多同心圆,这些同心圆轨迹叫做磁道(Track),磁道从外向内从 0 开始顺序编号。所有盘面上的同一磁道构成一个圆柱,通常称做柱面(Cylinder),每个圆柱上的磁头由上而下从 0 开始编号。每个磁道会被分成许多段圆弧,每段圆弧叫做一个扇区,扇区从 1 开始编号,每个扇区中的数据作为一个单元同时读出或写入,操作系统以扇区(Sector)形式将信息存储在硬盘上,每个扇区包括 512 个字节的数据和一些其他信息。
盘片
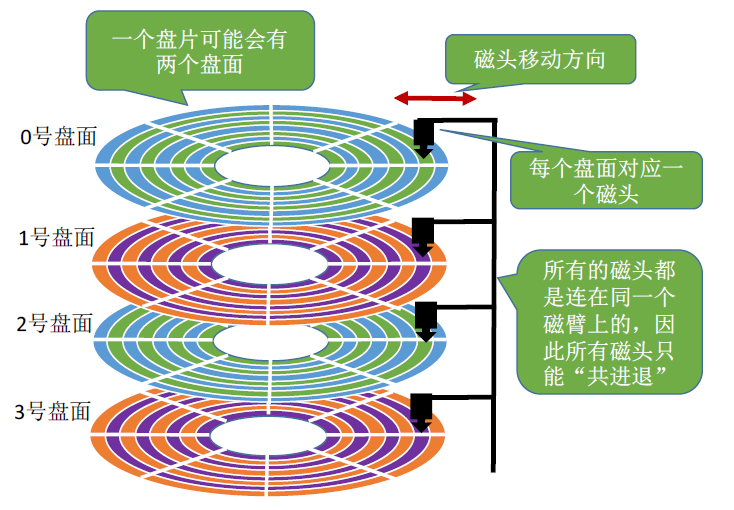
一个磁盘(如一个 1T 的机械硬盘)由多个盘片(如下图中的 0 号盘片)叠加而成。
盘片的表面涂有磁性物质,这些磁性物质用来记录二进制数据。因为正反两面都可涂上磁性物质,故一个盘片 可能会有 两个盘面。
磁道、扇区
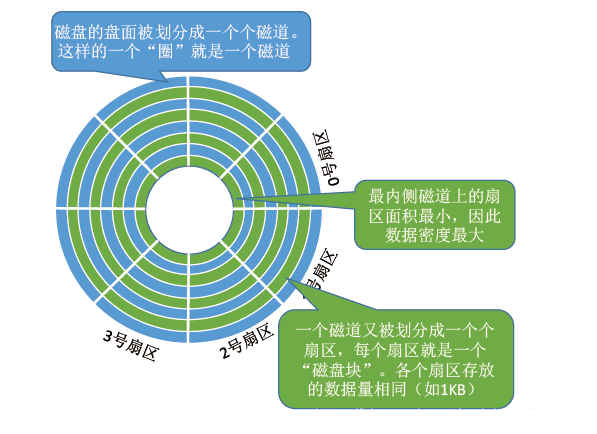
每个盘片被划分为一个个磁道,每个磁道又划分为一个个扇区。其中,最内侧磁道上的扇区面积最小,因此数据密度最大(但所能存储的数据量相同)。
文件系统中有逻辑块(Block)的概念,其中每个 block 大小为 4KB,是文件存储的最小单位。一个 4KB 的 block 通常由 8 个扇区组成,每个扇区为 512 字节。
柱面
每个盘面对应一个磁头(读写头)。所有的磁头都是连在同一个磁臂上的,因此所有磁头只能“共进退”。
所有盘面中相对位置相同的磁道组成柱面。如下图所示。
磁盘的物理地址
由上,可用(柱面号,盘面号,扇区号)组合来寻址,即定位任意一个“磁盘块”,这种方式被称为 CHS 寻址(Cylinder-Head-Sector)。
我们经常提到文件数据存放在外存中的几号块(逻辑地址),这个块号就可以转换成(柱面号,盘面号,扇区号)的 CHS 地址形式。
可根据该地址读取一个“块(Block)”,操作如下:
根据“柱面号”移动磁臂,让磁头指向指定柱面;
激活指定盘面对应的磁头;
磁盘旋转的过程中,指定的扇区会从磁头下面划过,这样就完成了对指定扇区的读 / 写。
LBA(逻辑块寻址)
LBA(Logical Block Addressing,逻辑块寻址)是一种硬盘寻址方式,它将硬盘视为一块扁平的逻辑存储区域,每个存储块(通常是扇区)都有一个唯一的逻辑地址 。这种寻址方式使得操作系统能够通过逻辑地址而不是物理位置来访问硬盘数据,从而简化了硬盘的管理和数据访问。
LBA 工作原理
LBA 采用的是一种简单的线性寻址方法,每个存储块(通常是 512 字节的扇区)都有一个唯一的编号。硬盘的每个逻辑块都有一个逻辑块号,操作系统和磁盘控制器通过这个逻辑地址来访问相应的物理存储区域。
LBA 地址 :LBA 地址是一个简单的整数,它代表了硬盘上每个扇区的逻辑编号。例如,LBA 地址 0 表示硬盘的第一个扇区,LBA 地址 1 表示第二个扇区,以此类推。
扇区大小 :LBA 通常与硬盘的扇区大小(通常为 512 字节,现代硬盘也可能使用 4K 扇区)相关。每个 LBA 地址对应一个固定大小的数据块(扇区)。操作系统通过 LBA 地址进行读写操作,不需要知道硬盘的具体物理结构。
逻辑到物理的映射 :硬盘的控制器负责将 LBA 地址转换为硬盘的物理位置(即 CHS 地址)。当操作系统通过 LBA 进行寻址时,硬盘控制器会在内部进行地址转换,将逻辑地址映射到实际的物理位置(柱面、磁头和扇区)。
LBA-CHS 转换公式
LBA 转换成 CHS 公式:
Cylinder = LBA / (Heads per Cylinder * Sector Per Track)
其中,Cylinder 表示柱面数,Heads per Cylinder 表示每个柱面的磁头数,Sector Per Track 表示每个磁道的扇区数,Head 表示磁头数,Sector 表示扇区数。
磁盘文件存储
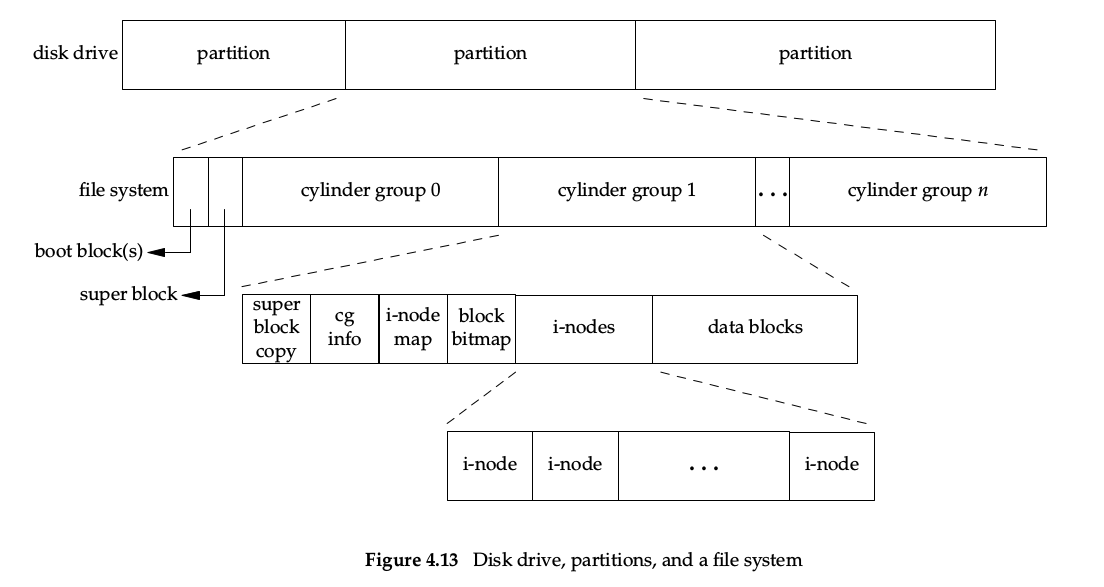
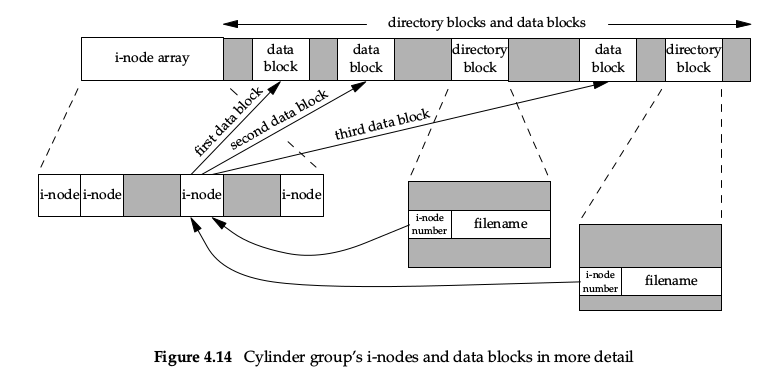
APUE P91,4.14 节的图很清楚的说明了磁盘、分区、文件系统、文件节点、数据块之间的关系,看图:
一整块磁盘可以划分为多个分区,每个分区都包含一个超级块和 n 个柱面组。每个柱面组下会包含 inode bitmap 和 inodes 以及 blcok bitmap 和 data blocks。出于数据安全考虑,超级块不仅仅存储在分区的起始位置,也会在某些柱面组(而非全部)下进行拷贝备份。
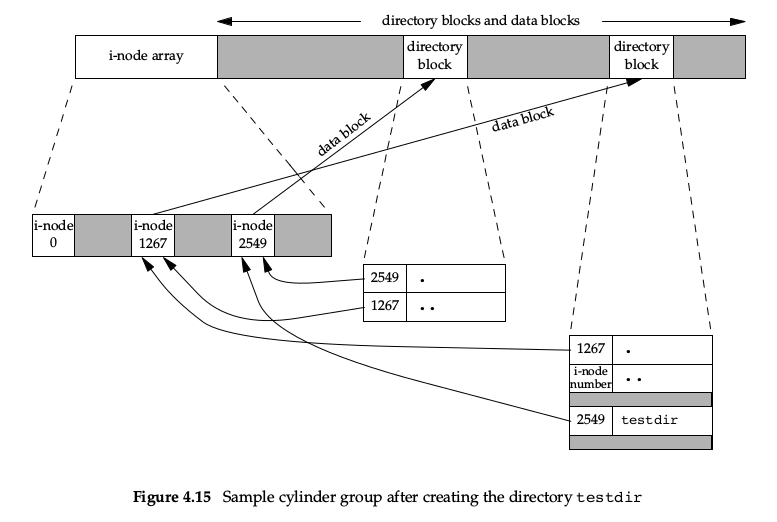
当我们使用命令 mkdir testdir 创建一个目录后,磁盘结构如下图:
i-node 2549(8683543) 指向一个目录块,即 testdir 目录的实际数据块。
i-node 2549 的引用计数为 2,任何叶子目录的引用计数都是 2:一个来自父目录 .. 的引用、一个来自自身目录 . 的引用。
i-node 2549 的父目录为 1267(8683541),同样指向一个目录数据块,里边包含指向自身的 .,指向其父目录的 ..,和包含的目录项 2549:testdir。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 /home/abc . └── apue └── testdir 2 directories, 0 files /home/abc/apue 总计 12 8683542 drwxr-xr-x 3 root root 4096 11 月 11 16:44 . 8683541 drwxr-xr-x 3 root root 4096 11 月 11 16:44 .. 8683543 drwxr-xr-x 2 root root 4096 11 月 11 16:44 testdir /home/abc 总计 12 8683541 drwxr-xr-x 3 root root 4096 11 月 11 16:44 . 8663454 drwxr-xr-x 9 root root 4096 11 月 11 16:43 .. 8683542 drwxr-xr-x 3 root root 4096 11 月 11 16:44 apue
文件基本操作(抽象)
Linux 文件系统的 10 个基本抽象(系统调用):
open/close/(creat)
read/write/lseek/(tell)
fstat/ftruncate
unlink/mkdir/dup
系统调用
功能描述
参数
open
打开文件,返回文件描述符,允许对文件进行读写操作
pathname(文件路径), flags(打开方式), mode(文件权限,可选)
close
关闭文件描述符,释放文件资源
fd(文件描述符)
creat
创建一个文件,如果文件已存在则清空文件内容
pathname(文件路径), mode(文件权限)
read
从打开的文件中读取数据
fd, buf(存储数据的缓冲区), count(读取字节数)
write
向打开的文件中写入数据
fd, buf(写入数据的缓冲区), count(写入字节数)
lseek
移动文件指针位置,用于随机读写
fd, offset(偏移量), whence(偏移起点)
tell
返回文件指针当前的位置
fd
fstat
获取文件的相关信息
fd, statbuf(存储信息的缓冲区)
ftruncate
截断文件,使文件的大小缩小到指定长度
fd, length(文件的目标长度)
unlink
inode 引用计数减一,当 inode 引用计数为 0 时才会删除文件
pathname(文件路径)
mkdir
创建目录
pathname(目录路径), mode(目录权限)
dup
复制文件描述符,创建一个新的描述符引用相同的文件
fd(原文件描述符)
文件系统架构
VFS 与文件系统
Linux 支持多种文件系统,为了让应用程序能够对所有系统不加区分的操作,Linux 提供了一个抽象层,这个抽象层介于应用程序和具体的文件系统之间,就像一个开关一样将用户请求转换到具体文件系统系统去,让具体文件系统去实现对应的操作,最后再将结果返回给用户。
这种引入一个抽象层次的设计思想,即“上层不依赖于具体实现,而依赖于接口;下层也不用关心调用,只用实现接口”,就算面向对象里的“面向接口编程”吧。
块设备驱动架构
Linux VFS
文件系统分类
从功能的角度来看,文件系统可以分为以下几类:
磁盘文件系统(ext3、ext4、xfs、fat 以及 ntfs 等)
网络文件系统(nfs、smbfs/cifs、ncp 等)
虚拟文件系统(procfs、sysfs、sockfs、pipefs 等)
Linux 内核实例使用 VFS 来处理目录和文件的层次结构(一棵树)。通过挂载操作,新的文件系统将被添加为 VFS 子树。
文件系统模型
常见的文件系统模型(任何实现的文件系统都需要符合该模型)包括几种明确定义的实体: superblock, inode, file 和 dentry。这些实体是文件系统的元数据(包含有关数据或其他元数据的信息)。
super_block
超级块(super block)存储了挂载文件系统所需的信息,是针对文件系统级别的概念 :
inode 和块的位置;
文件系统块大小;
最大文件名长度;
最大文件大小;
根 inode 的位置。
本地化 :
对于磁盘文件系统,超级块在磁盘的 第一个块 中有对应项(文件系统控制块)。
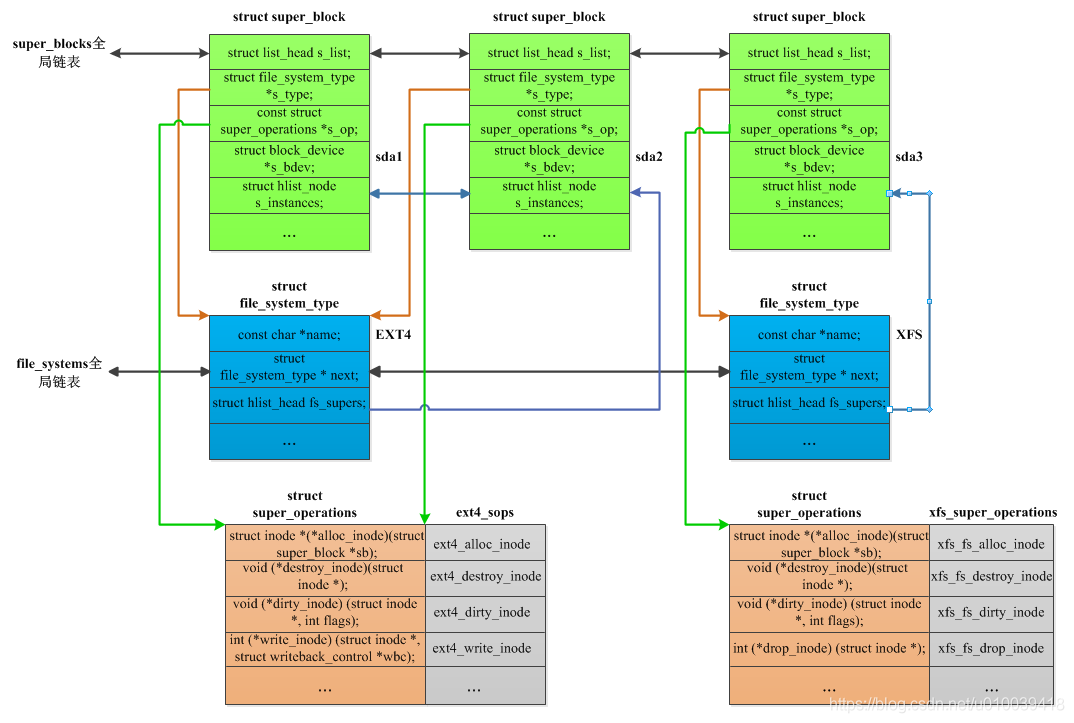
在 VFS 中,所有文件系统的超级块 都保留在类型为 struct super_block 的结构 列表中 ,操作方法则保留在类型为 struct super_operations 的结构中。
文件系统都有一个根节点 root,其他的节点都是通过 root 向下查找而来,查找的手段都是通过文件名匹配 。
每个超级块实例对应一个挂载的文件系统,如果已经挂载,就是活动超级块,当然一个超级块可以挂载到多个分区。
inode
inode(索引节点)保存了有关文件的信息。注意这里的文件指的是泛指意义上的文件,常规文件、目录、特殊文件(管道、fifo)、块设备、字符设备、链接或可以抽象为文件的任何内容都包括在内。
inode 存储了以下信息(可以分为两个部分,一个是文件状态信息、一个是保存的数据,状态信息叫元数据):
文件类型;
文件大小;
访问权限;
访问或修改时间;
数据在磁盘上的位置(指向包含数据的磁盘块的指针)。
索引节点和文件容易混淆,inode 和 file 的设计目的是不一样的,inode 主要提供了对文件节点创建、命名、删除等操作方法,而 file 则关注文件中数据的读写 。
通常,inode 不包含文件名。文件名由 dentry 实体存储。这样,一个 inode 可以有多个名称(硬链接)。
目录也是用 inode 表示,只不其内容是录下的文件名与其 inode 编号的对应表。
本地化 :
与 superblock 类似,inode 也有磁盘对应项。磁盘上的 inodes 通常分组存储在一个专用区域(inode 区域)中,与数据块区域分开;作为 VFS 实体,inode 由 struct inode 结构表示,并由 struct inode_operations 结构定义与之相关的操作方法。
符号链接(symbolic links)和硬链接(hard links)都是由 inode 表示。
符号链接的 inode 数据段包含一个路径字符串,指向链接的地址。
多个硬链接实际是由同一个 inode 表示,只不过 inode 中有一个引用计数器,记住了总共有多少个硬链接。
硬链接不能是目录,因为每个目录由一个 inode 表示,如果多个目录指向同一个 inode,那么从该目录向上查找就会发现由多个 parent,这会破坏目录树的结构。更糟糕的是,如果把一个目录和它的子目录互相硬链接会发生什么?进入这个目录就意味着直接进入其子目录,进入子目录又进一步进入父目录,产生死循环。
file
file 是文件系统模型中距离用户最近的组件。file 对象是文件被打开的时候创建的,该结构体仅作为 VFS 在内存中的实体存在,没有在磁盘上的物理对应物。
inode 抽象了磁盘上的文件,而 file 结构抽象了打开的文件。从进程的角度来看,file 实体抽象了文件。然而,从文件系统实现的角度来看,inode 才是抽象文件的那个实体。
file 结构维护了以下信息:
文件游标位置;
文件打开权限;
指向关联 inode 的指针(最终是 inode 的索引)。
本地化 :
与之关联的 VFS 实体是 struct file 结构,与之相关的操作方法由 struct file_operations 结构表示。
定义 file 是为了让进程对文件的记录是私有的(进程间互相独立),父子进程对文件共享。由于一个文件可以被多个进程打开,所以文件指针要放在 file 对象中而不是 inode 对象中。换句话说,一个文件与唯一的一个 inode 对应,多个进程打开同一文件进行 I/O 操作(如以什么模式打开、读取的偏移等),不能直接修改 inode 对象的数据,因为对 inode 的修改对所有进程可见)。
dentry
名字查找是 VFS 当中非常复杂的一个部分。前面说了查找 inode 是通过名字匹配来实现的,但是并不是每个文件系统都能够快速的实现名字到 inode 的转换。于是 VFS 实现了 dcache,为快速名字查找提供了可靠的保障。VFS 处理了所有文件路径名的管理操作,在底层文件系统能够看到他们之前,将其转换为 dcache 的入口。
dcache 称之为高速目录缓存,由许多 dentry 组成,每个 dentry 对应到系统中的一个文件名。当前活动的文件名字和最近使用的文件名字都缓存在 dcache 中。每个 dentry 的父节点必须在 dcache 中,只要在 dcache 中存在一个目录项,那么相应的 inode 就在 inode 高速缓存中。反过来,如果 inode 在 inode 高速缓存中,那么它一定引用 dcache 中的一个 dentry。也就是可以理解为 dcache 的存在就是为了加速文件名字到具体 inode 的转换,VFS 三个字母中的 S-switch 和这个功能息息相关。
dcache 是一个树状结构,每个 dcache 节点对应一个目录,也就是指定名字的 inode。一个 inode 可以和树中的多个 dcache 节点联系,因为硬链接可以在多个地方指向同一个节点。
dentry 是目录或文件路径的特定部分。例如,对于路径 /bin/vi,将为 /, bin 和 vi 创建 dentry 对象(总共 3 个 dentry 对象)。
一个打开的 file 一定会指向 dentry,而一个 dentry 又会指向 inode,所以 dentry 可以看作是 file 到 inode 的 switch。
在 VFS 中,dentry 实体由 struct dentry 结构表示,与之相关的操作方法在 struct dentry_operations 结构中定义。
请注意目录项和目录区别,目录不过是 inode 的一种形式(目录是一个特殊的文件)。
注册与注销文件系统
Linux 内核支持约 50 种文件系统。如果文件系统(更准确地说,文件系统类型)没有注册,那么自然就无法使用。文件系统注册可以有两种方式:
一种是将文件系统编译到内核里,这样系统启动就会自动完成注册;
一种是将文件系统编译成模块,在模块载入的时候注册。
当文件系统编译到内核时,在 start_kernel() 就会调用注册函数,如 rootfs、proc 等,而永远不会调用注销函数。当文件编译为模块时,在模块的 init() 函数中就会调用注册函数,在模块的 exit() 函数中会调用注销函数。
注册文件系统
注册文件系统并不复杂,可以直接看源代码。但是,要理解原理需要先理解描述特定文件系统的结构 struct file_system_type。文件系统类型最关键的是要 提供两个操作——挂载和卸载 ,对应到 file_system_type 就是函数指针成员 mount 和 kill_sb。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 struct file_system_type { const char * name; int fs_flags; #define FS_REQUIRES_DEV 1 #define FS_BINARY_MOUNTDATA 2 #define FS_HAS_SUBTYPE 4 #define FS_USERNS_MOUNT 8 #define FS_USERNS_DEV_MOUNT 16 #define FS_RENAME_DOES_D_MOVE 32768 struct dentry * (*mount )(struct file_system_type *, int , const char *, void *); void (*kill_sb)(struct super_block*); struct module * owner ; struct file_system_type * next ; struct hlist_head fs_supers ; };
注册的思路上非常简单,如果找到同名字的文件系统就说明已经注册了,返回 -EBUSY。反之 find_filesystem() 会获取到最后一个文件系统的 next 指针,将其指向新的文件系统就完成注册了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 static struct file_system_type *file_systems ;static DEFINE_RWLOCK (file_systems_lock) ;int register_filesystem (struct file_system_type* fs) { int res = 0 ; struct file_system_type ** p ; BUG_ON(strchr (fs->name, '.' )); if (fs->next) return -EBUSY; write_lock(&file_systems_lock); p = find_filesystem(fs->name, strlen (fs->name)); if (*p) res = -EBUSY; else *p = fs; write_unlock(&file_systems_lock); return res; } EXPORT_SYMBOL(register_filesystem);
不妨看一下 find_filesystem() 的实现。所有的文件系统类型形成一个链表,链表头存放在一个叫 file_systems 的全局变量中。所以不需要特殊的参数来传递链表头。
1 2 3 4 5 6 7 static struct file_system_type** find_filesystem (const char * name, unsigned len) { struct file_system_type ** p ; for (p = &file_systems; *p; p = &(*p)->next) if (strlen ((*p)->name) == len && strncmp ((*p)->name, name, len) == 0 ) break ; return p; }
注销文件系统
注销文件系统的代码也比较简单,直接看源代码。这里 tmp 作为一个二级指针,它会向后移动,假设这里移动到了 fs,这时 *tmp 和 fs 指向同一位置,需要注意的是 tmp 实际上是上一个节点的 next 地址,因此 *tmp = fs->next 实际上是改变上一个节点 next 的指向,也就是让其跳过 fs、指向 fs 的下一个节点。接下来由于 fs 已经被 file_systems 链表所抛弃,我们必须将 fs->next 清空。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 int unregister_filesystem (struct file_system_type* fs) { struct file_system_type ** tmp ; write_lock(&file_systems_lock); tmp = &file_systems; while (*tmp) { if (fs == *tmp) { *tmp = fs->next; fs->next = NULL ; write_unlock(&file_systems_lock); synchronize_rcu(); return 0 ; } tmp = &(*tmp)->next; } write_unlock(&file_systems_lock); return -EINVAL; } EXPORT_SYMBOL(unregister_filesystem);
rootfs 和 ramfs 注册
以下是内核注册虚拟文件系统的示例。
注册 rootfs 是在 init_rootfs() 中完成的(将文件系统编译到内核里),主要工作就是注册 rootfs_fs_type。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 static struct file_system_type rootfs_fs_type = .name = "rootfs" , .mount = rootfs_mount, .kill_sb = kill_litter_super, }; int __init init_rootfs (void ) { int err; err = register_filesystem(&rootfs_fs_type); return err; }
注册 ramfs 是在 module 加载时初始化注册的(将文件系统编译成模块)。
1 2 3 4 5 6 7 8 9 10 11 12 static struct file_system_type ramfs_fs_type = .name = "ramfs" , .mount = ramfs_mount, .kill_sb = ramfs_kill_sb, .fs_flags = FS_USERNS_MOUNT, }; static int __init init_ramfs_fs (void ) { return register_filesystem(&ramfs_fs_type); } module_init(init_ramfs_fs)
数据结构
各对象之间的关系
这里,首先通过一个示例给出下面各种数据结构的组织关系,然后再详细介绍各类数据结构。
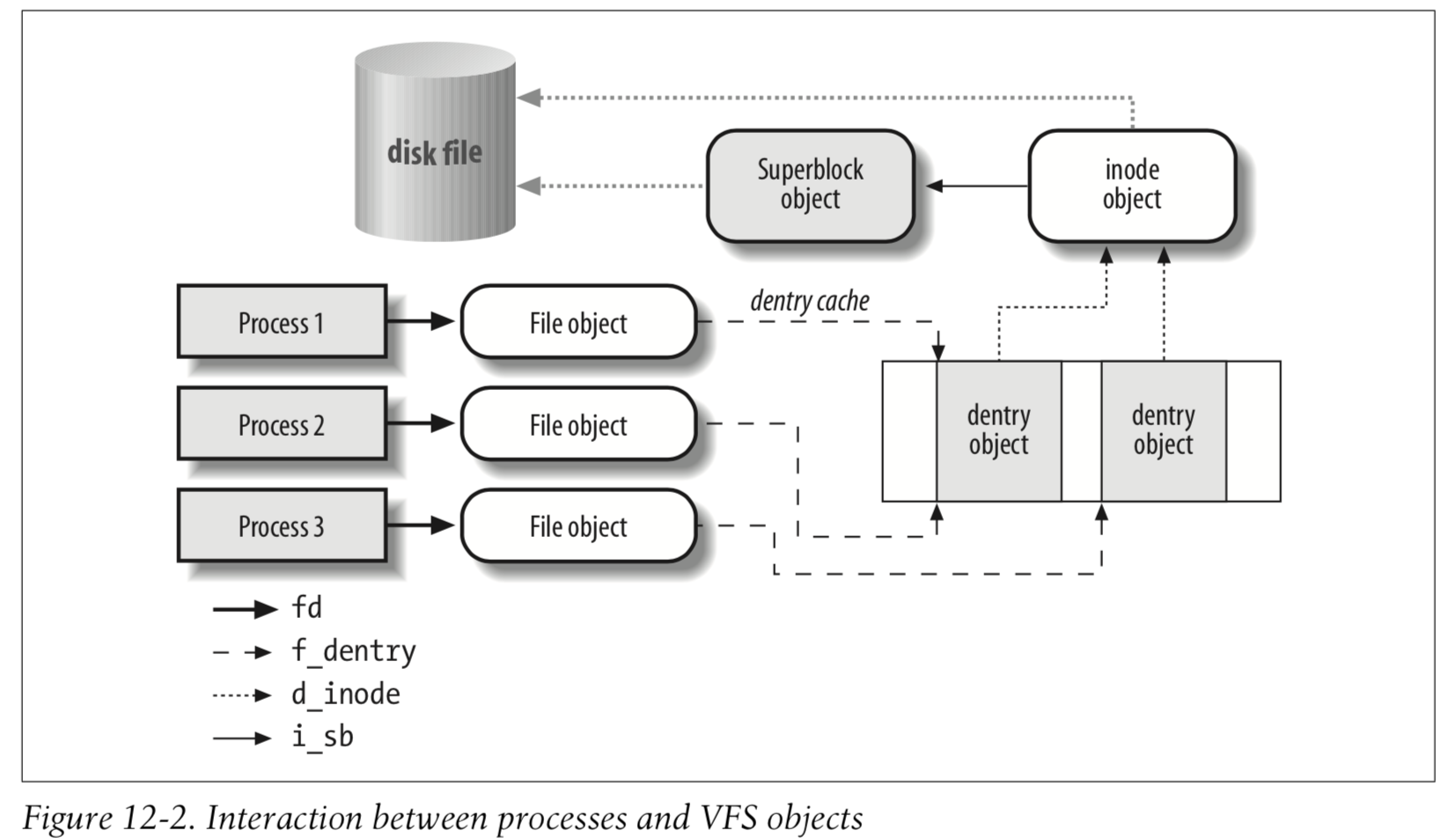
Figure 12-2 illustrates with a simple example how processes interact with files. Three different processes have opened the same file, two of them using the same hard link. In this case, each of the three processes uses its own file object, while only two dentry objects are required—one for each hard link. Both dentry objects refer to the same inode object, which identifies the superblock object and, together with the latter, the common disk file.
超级块
super_block
超级块既作为物理实体(磁盘上的实体)存在,也作为 VFS 实体(在 struct super_block 结构中)存在。超级块仅包含元信息,并用于从磁盘中读取和写入元数据(如 inode、目录项)。超级块(以及隐式的 struct super_block 结构)将包含有关所使用的块设备、inode 列表、文件系统根目录的 inode 指针以及超级块操作的指针的信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 struct super_block { struct list_head s_list ; dev_t s_dev; unsigned char s_blocksize_bits; unsigned long s_blocksize; loff_t s_maxbytes; struct file_system_type * s_type ; const struct super_operations * s_op ; struct dentry * s_root ; int s_count; atomic_t s_active; struct list_head s_inodes ; struct list_head s_mounts ; struct hlist_node s_instances ; fmode_t s_mode; };
相关函数:
sget 构造函数,如果没有从已经挂载的文件系统找到需要的 super_block 就会调用 alloc_super 分配一个。
put_super 析构函数,当引用计数减少到 0 时才会调用 destroy_super 真正释放。
super_operations
主要包括对 inode 数据结构的操作(操作系统 VFS 层面),注意不是对 inode 的操作(磁盘层面),对 inode 的操作由 inode_operations 来完成。如:alloc_inode、destroy_inode、dirty_inode 等等。
所有的函数由 VFS 调用,都在进程上下文调用,所有的函数都可能阻塞。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 struct super_operations { struct inode *(*alloc_inode )(struct super_block *sb ); void (*destroy_inode)(struct inode *); void (*dirty_inode) (struct inode *, int flags); int (*write_inode) (struct inode *, struct writeback_control *wbc); int (*drop_inode) (struct inode *); void (*evict_inode) (struct inode *); void (*put_super) (struct super_block *); int (*sync_fs)(struct super_block *sb, int wait); int (*freeze_fs) (struct super_block *); int (*unfreeze_fs) (struct super_block *); int (*statfs) (struct dentry *, struct kstatfs *); int (*remount_fs) (struct super_block *, int *, char *); void (*umount_begin) (struct super_block *); int (*show_options)(struct seq_file *, struct dentry *); int (*show_devname)(struct seq_file *, struct dentry *); int (*show_path)(struct seq_file *, struct dentry *); int (*show_stats)(struct seq_file *, struct dentry *); #ifdef CONFIG_QUOTA ssize_t (*quota_read)(struct super_block *, int , char *, size_t , loff_t ); ssize_t (*quota_write)(struct super_block *, int , const char *, size_t , loff_t ); #endif int (*bdev_try_to_free_page)(struct super_block*, struct page*, gfp_t ); int (*nr_cached_objects)(struct super_block *); void (*free_cached_objects)(struct super_block *, int ); };
索引节点
inode
inode 既存在于 VFS 中(内存中),也存在于磁盘中(对于 UNIX、HFS 以及 NTFS 等)。VFS 中的 inode 由 struct inode 结构表示。和 VFS 中的其他结构一样, struct inode 是通用结构,涵盖了所有支持的文件类型的选项,甚至包括那些没有关联磁盘实体的文件类型(比如 FAT 文件系统)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct inode { umode_t i_mode; kuid_t i_uid; kgid_t i_gid; const struct inode_operations * i_op ; struct super_block * i_sb ; struct address_space * i_mapping ; struct address_space i_data ; loff_t i_size; struct timespec i_atime ; struct timespec i_mtime ; struct timespec i_ctime ; const struct file_operations * i_fop ; void * i_private; };
相关函数:
new_inode 构造函数,调用 alloc_inode 从 inode_cachep 分配索引节点。
inode_operations
对 inode 的操作,包括 create、lookup、mkdir、rmdir、link、unlink 等等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 struct inode_operations { struct dentry * (*lookup ) (struct inode *,struct dentry *, unsigned int ); void * (*follow_link) (struct dentry *, struct nameidata *); int (*permission) (struct inode *, int ); struct posix_acl * (*get_acl )(struct inode *, int ); int (*readlink) (struct dentry *, char __user *,int ); void (*put_link) (struct dentry *, struct nameidata *, void *); int (*create) (struct inode *,struct dentry *, umode_t , bool ); int (*link) (struct dentry *,struct inode *,struct dentry *); int (*unlink) (struct inode *,struct dentry *); int (*symlink) (struct inode *,struct dentry *,const char *); int (*mkdir) (struct inode *,struct dentry *,umode_t ); int (*rmdir) (struct inode *,struct dentry *); int (*mknod) (struct inode *,struct dentry *,umode_t ,dev_t ); int (*rename) (struct inode *, struct dentry *, struct inode *, struct dentry *); int (*setattr) (struct dentry *, struct iattr *); int (*getattr) (struct vfsmount *mnt, struct dentry *, struct kstat *); int (*setxattr) (struct dentry *, const char *,const void *,size_t ,int ); ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t ); ssize_t (*listxattr) (struct dentry *, char *, size_t ); int (*removexattr) (struct dentry *, const char *); int (*fiemap)(struct inode *, struct fiemap_extent_info *, u64 start, u64 len); int (*update_time)(struct inode *, struct timespec *, int ); int (*atomic_open )(struct inode *, struct dentry *, struct file *, unsigned open_flag, umode_t create_mode, int *opened); } ____cacheline_aligned;
进程与文件
文件是和进程息息相关的,和文件相关的结构包括:
task_struct: 进程的表示,包括 fs_struct 和 files_struct
fs_struct: 进程和文件系统的关系
files_struct: 用于将 fd 转换为 file
file: 文件的表示
file
1 2 3 4 5 6 7 8 9 10 11 12 13 struct file { struct path f_path ; struct inode * f_inode ; const struct file_operations * f_op ; atomic_long_t f_count; unsigned int f_flags; fmode_t f_mode; loff_t f_pos; struct fown_struct f_owner ; void * private_data; struct address_space *f_mapping ; };
相关函数:
alloc_file 调用 get_empty_filp 从 filp_cachep 分配一个文件。
file_operations
这个操作集包含了对文件的所有操作,如读取、写入、打开和关闭等等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 struct file_operations { struct module *owner ; loff_t (*llseek) (struct file *, loff_t , int ); ssize_t (*read) (struct file *, char __user *, size_t , loff_t *); ssize_t (*write) (struct file *, const char __user *, size_t , loff_t *); ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long , loff_t ); ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long , loff_t ); int (*readdir) (struct file *, void *, filldir_t ); unsigned int (*poll) (struct file *, struct poll_table_struct *) ; long (*unlocked_ioctl) (struct file *, unsigned int , unsigned long ); long (*compat_ioctl) (struct file *, unsigned int , unsigned long ); int (*mmap) (struct file *, struct vm_area_struct *); int (*open) (struct inode *, struct file *); int (*flush) (struct file *, fl_owner_t id); int (*release) (struct inode *, struct file *); int (*fsync) (struct file *, loff_t , loff_t , int datasync); int (*aio_fsync) (struct kiocb *, int datasync); int (*fasync) (int , struct file *, int ); int (*lock) (struct file *, int , struct file_lock *); ssize_t (*sendpage) (struct file *, struct page *, int , size_t , loff_t *, int ); unsigned long (*get_unmapped_area) (struct file *, unsigned long , unsigned long , unsigned long , unsigned long ) ; int (*check_flags)(int ); int (*flock) (struct file *, int , struct file_lock *); ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t , unsigned int ); ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t , unsigned int ); int (*setlease)(struct file *, long , struct file_lock **); long (*fallocate)(struct file *file, int mode, loff_t offset, loff_t len); int (*show_fdinfo)(struct seq_file *m, struct file *f); };
task_struct
进程中与文件相关的两个成员。
1 2 3 4 5 struct task_struct { struct fs_struct * fs ; struct files_struct * files ; };
fs_struct
主要包含两个路径,一个是当前工作目录,一个是工作目录所在文件系统的根目录。主要体现了进程和具体文件系统的关系。
1 2 3 4 5 6 7 8 9 10 11 12 13 struct path { struct vfsmount * mnt ; struct dentry * dentry ; }; struct fs_struct { int users; int umask; struct path root ; struct path pwd ; };
files_struct
我们通常说的 fd 是一个整数,而这个整数正好可以作为下标,从而从 files_struct 中获得 file 结构。具体查找是通过 fdt->fd[fd] 来找到对应的 file(在默认数量内,这里的 file 地址就是 fd_array[fd])。
1 2 3 4 5 6 7 8 9 10 11 struct files_struct { atomic_t count; struct fdtable __rcu * fdt ; struct fdtable fdtab ; spinlock_t file_lock ____cacheline_aligned_in_smp; int next_fd; unsigned long close_on_exec_init[1 ]; unsigned long open_fds_init[1 ]; struct file * fd_array [NR_OPEN_DEFAULT ]; };
fdt
fdt 指针默认是指向 fdtab 的。当打开的文件数目比较多的时候,就需要重新分配一个 fdtable,并增大其 fd 数组和打开位图,然后将这个 fdt 指针指向新分配的 fdtable 资源。原来 fdt 所指向的内存会复制到新的 fdtable。
至于如何判断 fdt 是否指向动态 fdtable,也就是最后是否需要释放 fdt 所指向的内存,可以通过判断 fdt 和 &fdtab 的地址是否相等来确定。
从 fd 转换为 file 的关键数据结构就是 fdtable。
1 2 3 4 5 6 7 8 struct fdtable { unsigned int max_fds; struct file __rcu ** fd ; unsigned long * close_on_exec; unsigned long * open_fds; struct rcu_head rcu ; };
fd/close_on_exec/open_fds
如果打开的文件比较少,那么这个 fd 将指向 files_struct 的 fd_array。
如果打开的文件比较多,fdtable 本身就是动态分配的、fd 成员也是动态分配。所以,是否要释放 fd 所指空间很好判断,如果要释放 fdtable 就一定会释放 fd。对 fd 的分配会尝试 kmalloc() 和 vmalloc() 两种方法。
另外,close_on_exec 与 open_fds 的行为同 fd,如果 fdtable 是动态分配的,那么他们也必然是动态分配的。
目录项
目录操作使用 struct dentry 结构体。它的主要任务是在索引节点和文件名之间建立链接。
dentry
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct dentry { struct dentry * d_parent ; struct qstr d_name ; struct inode * d_inode ; const struct dentry_operations * d_op ; void * d_fsdata; struct super_block * d_sb ; union { struct list_head d_child ; struct rcu_head d_rcu ; } d_u; struct list_head d_subdirs ; };
相关函数:
d_alloc 构造函数,从 dentry_cache 分配一个 negative 目录项。
dput 析构函数,当引用计数为 0 时调用 dentry_kill 释放目录项。
dentry_operations
由于 dentry 主要供 VFS 使用,所以操作集中的函数一般情况下也不需要具体文件系统去实现。这里的函数是针对 dentry 的操作,如 d_revalidate、d_hash、d_compare、d_delete、 d_release、d_prune 等等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct dentry_operations { int (*d_revalidate)(struct dentry *, unsigned int ); int (*d_weak_revalidate)(struct dentry *, unsigned int ); int (*d_hash)(const struct dentry *, const struct inode *, struct qstr *); int (*d_compare)(const struct dentry *, const struct inode *, const struct dentry *, const struct inode *, unsigned int , const char *, const struct qstr *); int (*d_delete)(const struct dentry *); void (*d_release)(struct dentry *); void (*d_prune)(struct dentry *); void (*d_iput)(struct dentry *, struct inode *); char *(*d_dname)(struct dentry *, char *, int ); struct vfsmount *(*d_automount )(struct path *); int (*d_manage)(struct dentry *, bool ); } ____cacheline_aligned;
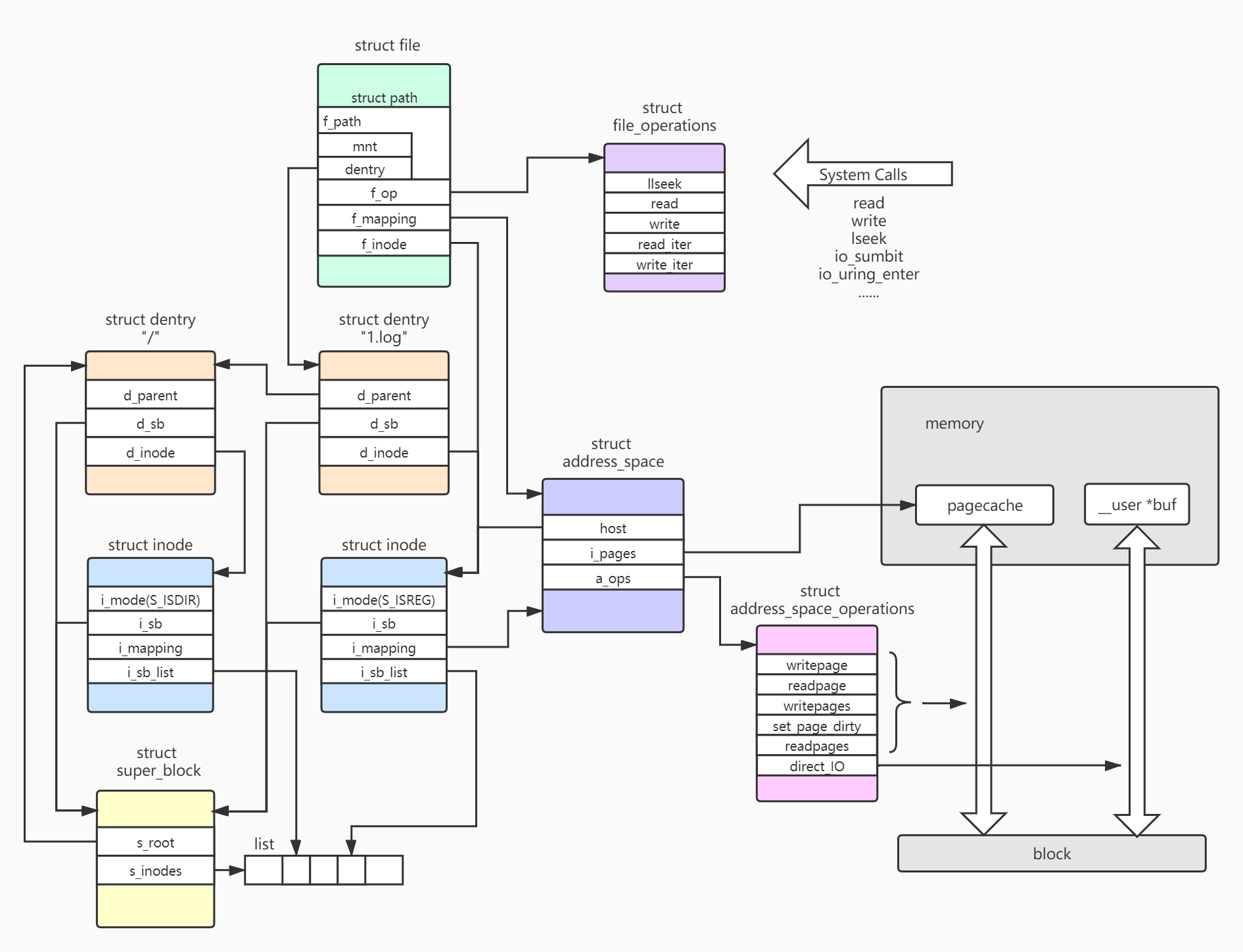
数据结构关系图
基本操作
从 fd 获取 file
查找 fd 对应的 file 结构的线路图为:current -> files_struct -> fdtable -> file,具体可以参考 fget 函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 struct file* fget (unsigned int fd) { struct file * file ; struct files_struct * files = rcu_read_lock(); file = fcheck_files(files, fd); if (file) { if (file->f_mode & FMODE_PATH || !atomic_long_inc_not_zero(&file->f_count)) file = NULL ; } rcu_read_unlock(); return file; } static inline struct file* fcheck_files (struct files_struct* files, unsigned int fd) { struct file * file =NULL ; struct fdtable * fdt = if (fd < fdt->max_fds) file = rcu_dereference_check_fdtable(files, fdt->fd[fd]); return file; } #define rcu_dereference_check_fdtable(files, fdtfd) \ (rcu_dereference_check((fdtfd), \ lockdep_is_held(&(files)->file_lock) || \ atomic_read(&(files)->count) == 1 || \ rcu_my_thread_group_empty())) #define files_fdtable(files) \ (rcu_dereference_check_fdtable((files), (files)->fdt))
块设备驱动
简介
字符设备
字符设备是一种顺序的数据流设备,对字符设备的读写是以字节为单位进行的,这些字符连续地形成一个数据流,字符设备没有缓存区,对于字符设备的读写是实时的。字符设备包括键盘、鼠标、串口、终端等。
块设备
块设备是一种具有一定结构的随机存取设备,对块设备的读写是以块为单位进行的,块设备使用缓存区来存放数据,待条件满足后,将数据从缓存区一次性写入到设备,或者从设备一次性读取到缓存区。块设备包括硬盘、SSD 等存储介质。
特性
字符设备
块设备
访问方式
顺序访问
随机访问
类型
数据流设备
存储设备
读写单位
以字节为单位
以块为单位
缓存支持
没有缓存区,实时读写
有缓存区,非实时
调用层
由应用层程序调用
由文件系统程序调用
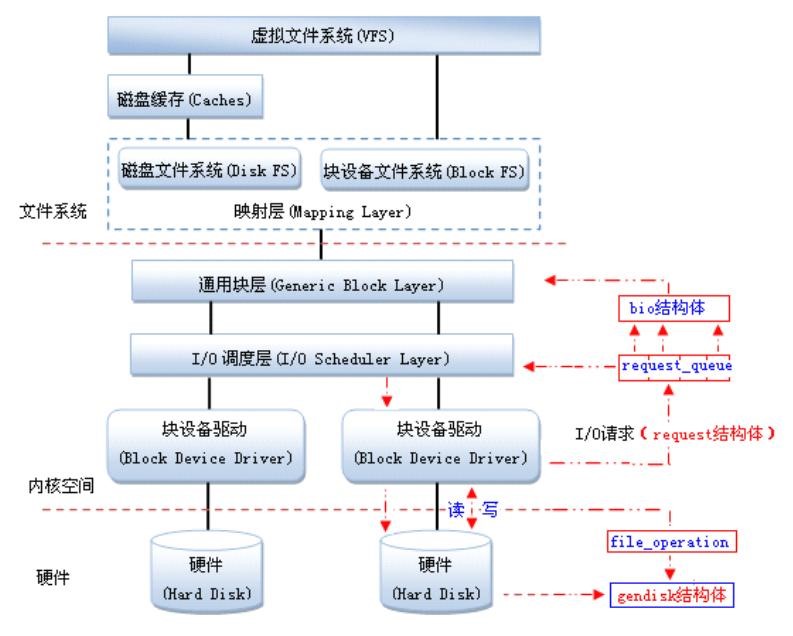
块设备的速度通常比字符设备的速度快得多,并且它们的性能也很重要。与字符设备相比,使用块设备更加复杂。字符设备只有当前位置,而块设备必须能够移动到设备上的任何位置,以提供对数据的随机访问 。为了简化对块设备的操作,Linux 内核提供了一整个子系统,称为块 I/O(或块层)子系统。
块设备驱动架构
块设备使用请求队列,缓存并重排读写数据块的请求,用高效的方式读取数据;块设备的每个设备都关联了请求队列;对块设备的读写请求不会立即执行,这些请求会汇总起来,经过协同之后传输到设备。
注册块 I/O 设备
要注册块设备,请使用函数 register_blkdev()。要注销一个块设备,可以使用函数 unregister_blkdev()。
register_blkdev() 函数执行的唯一操作是 动态分配一个主设备号 (如果调用函数时主设备号参数为 0),并在 /proc/devices 中创建一个条目。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <linux/fs.h> #define MY_BLOCK_MAJOR 240 #define MY_BLKDEV_NAME "mybdev" static int my_block_init (void ) { int status; status = register_blkdev(MY_BLOCK_MAJOR, MY_BLKDEV_NAME); if (status < 0 ) { printk(KERN_ERR "unable to register mybdev block device\n" ); return -EBUSY; } } static void my_block_exit (void ) { unregister_blkdev(MY_BLOCK_MAJOR, MY_BLKDEV_NAME); }
通过 cat /proc/devices 命令,可得已注册的字符设备和块设备的主设备号和设备名称。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Character devices: 1 mem 4 /dev/vc/0 4 tty 4 ttyS ... 261 accel Block devices: 2 fd 7 loop 8 sd 9 md ... 259 blkext
注册磁盘
尽管 register_blkdev() 函数获取了主设备号,但它并没有向系统提供设备(磁盘)。为了创建和使用块设备(磁盘),我们使用在 linux/genhd.h 中定义的专门接口。
在 linux/genhd.h 中定义的有用函数是用于注册 / 分配磁盘、将其添加到系统中以及注销 / 卸载磁盘的函数。
alloc_disk() 函数用于分配磁盘,del_gendisk() 函数用于释放磁盘。使用 add_disk() 函数将磁盘添加到系统中 。
通常在模块初始化函数中使用 alloc_disk() 和 add_disk() 函数,而在模块退出函数中使用 del_gendisk() 函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <linux/fs.h> #include <linux/genhd.h> #define MY_BLOCK_MINORS 1 static struct my_block_dev { struct gendisk * gd ; } dev; static int create_block_device (struct my_block_dev* dev) { dev->gd = alloc_disk(MY_BLOCK_MINORS); add_disk(dev->gd); } static int my_block_init (void ) { create_block_device(&dev); } static void delete_block_device (struct my_block_dev* dev) { if (dev->gd) del_gendisk(dev->gd); } static void my_block_exit (void ) { delete_block_device(&dev); }
与字符设备一样,建议使用 my_block_dev 结构来存储描述块设备的重要元素。
请注意,在调用 add_disk() 函数之后(实际上,甚至包括调用期间),磁盘是活动的,可以随时调用其方法。因此,在驱动程序完全初始化并准备好响应对注册磁盘的请求之前,不应调用此函数 。
可以注意到,用于处理块设备(磁盘)的基本结构是 struct gendisk 结构。
在调用 del_gendisk() 函数后,如果仍然有用户(对设备调用了打开操作,但关联的释放操作尚未被调用),则 struct gendisk 结构可能继续存在(并且设备操作仍然可以调用)。一种解决方法是 记录设备的用户数 ,并仅在设备没有剩余用户后调用 del_gendisk() 函数。
gendisk 结构体
Linux 提供了一个 gendisk 数据结构体,用来表示一个独立的磁盘设备或分区,用于对底层物理磁盘进行访问。在 gendisk 中有一个类似字符设备中 file_operations 的硬件操作结构指针,是 block_device_operations 结构体。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 struct gendisk { int major; int first_minor; int minors; char disk_name[DISK_NAME_LEN]; char * (*devnode)(struct gendisk* gd, umode_t * mode); unsigned int events; struct hd_struct part0 ; const struct block_device_operations * fops ; struct request_queue * queue ; void * private_data; };
对于每一个分区来说,都有一个 hd_struct 结构体,用于描述该分区:
1 2 3 4 5 6 7 8 9 10 11 struct hd_struct { sector_t start_sect; sector_t nr_sects; sector_t alignment_offset; unsigned int discard_alignment; struct partition_meta_info * info ; };
如上所述,这样的结构体是通过 alloc_disk() 调用获得的,在将其作为参数传入 add_disk() 函数之前,必须填充其字段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <linux/blkdev.h> #include <linux/fs.h> #include <linux/genhd.h> #define NR_SECTORS 1024 #define KERNEL_SECTOR_SIZE 512 static struct my_block_dev { spinlock_t lock; struct request_queue * queue ; struct gendisk * gd ; } dev; static int create_block_device (struct my_block_dev* dev) { dev->gd = alloc_disk(MY_BLOCK_MINORS); if (!dev->gd) { printk(KERN_NOTICE "alloc_disk failure\n" ); return -ENOMEM; } dev->gd->major = MY_BLOCK_MAJOR; dev->gd->first_minor = 0 ; dev->gd->fops = &my_block_ops; dev->gd->queue = dev->queue ; dev->gd->private_data = dev; snprintf (dev->gd->disk_name, 32 , "myblock" ); set_capacity(dev->gd, NR_SECTORS); add_disk(dev->gd); return 0 ; }
如前所述,内核将磁盘视为一连串的 512 字节扇区 。实际上,设备可能具有不同大小的扇区。为了与这些设备一起工作, 内核需要了解实际扇区的大小,并且在所有操作中需要进行必要的转换 。
要向内核通知设备的扇区大小,必须在分配请求队列后设置请求队列的参数,使用 blk_queue_logical_block_size() 函数完成设置。内核生成的所有请求都将是该扇区大小的倍数,并相应地对齐。但是,设备和驱动程序之间的通信仍将以 512 字节大小的扇区进行,因此每次都需要进行转换(上述代码中调用 set_capacity() 函数时就是一个例子)。
block_device_operations 结构体
就像对于字符设备,需要完成 struct file_operations 中的操作一样,对于块设备,需要完成 struct block_device_operations 中的操作(来告诉 文件系统 ,块设备驱动的操作接口)。操作的关联是通过 struct gendisk 结构体中的 fops 字段完成的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct block_device_operations { int (*open)(struct block_device*, fmode_t ); int (*release)(struct gendisk*, fmode_t ); int (*locked_ioctl)(struct block_device*, fmode_t , unsigned , unsigned long ); int (*ioctl)(struct block_device*, fmode_t , unsigned , unsigned long ); int (*compat_ioctl)(struct block_device*, fmode_t , unsigned , unsigned long ); int (*direct_access)(struct block_device*, sector_t , void **, unsigned long *); int (*media_changed)(struct gendisk*); int (*revalidate_disk)(struct gendisk*); int (*getgeo)(struct block_device*, struct hd_geometry*); blk_qc_t (*submit_bio)(struct bio* bio); struct module * owner ; }
和字符设备驱动不同,块设备驱动的 block_device_operations 操作集中没有负责读和写数据的函数;在块设备驱动中,这些操作是由 request() 函数处理的 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <linux/fs.h> #include <linux/genhd.h> static struct my_block_dev { struct gendisk * gd ; } dev; static int my_block_open (struct block_device* bdev, fmode_t mode) { return 0 ; } static int my_block_release (struct gendisk* gd, fmode_t mode) { return 0 ; } struct block_device_operations my_block_ops =static int create_block_device (struct my_block_dev* dev) { dev->gd->fops = &my_block_ops; dev->gd->private_data = dev; }
请求队列
块设备驱动程序的核心是请求函数,包含请求处理过程。块设备的读写请求放置在请求队列中,在 struct gendisk 中,通过 struct request_queue *queue 指针指向请求队列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct request_queue { struct list_head queue_head ; struct request * last_merge ; struct elevator_queue * elevator ; request_fn_proc* request_fn; make_request_fn* make_request_fn; void * queuedata; struct list_head icq_list ; struct queue_limits limits ; struct blk_flush_queue * fq ; struct list_head requeue_list ; spinlock_t requeue_lock; struct delayed_work requeue_work ; };
参考资料:
http://mickyching.github.io/kernel/linux-vfs-introduction.html http://mickyching.github.io/kernel/linux-vfs-source-annotation.html 磁盘结构:https://blog.csdn.net/weixin_37641832/article/details/103217311
LBA: https://www.cnblogs.com/suv789/p/18536525
https://lan-cyl.github.io/linux kernel/Linux-kernel-05-vfs.html https://linux-kernel-labs-zh.xyz/labs/block_device_drivers.html https://linux-kernel-labs-zh.xyz/