Tail Queue 位于 /usr/include/x86_64-linux-gnu/sys/queue.h,可以include <sys/queue.h> 后直接使用。Queue 的所有源码都是宏定义,因此完全包含于 queue.h 当中,无需编译为库文件。
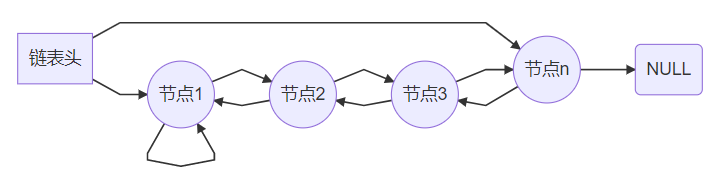
各种结构示意图
queue.h 包含以下几种数据结构:
单链表(Singly-linked List, SLIST)
单链尾队列(Singly-linked Tail queue, STAILQ)
双链表(List, LIST)
双链尾队列(Tail queue, TAILQ)
简单队列(Simple queue, SQUEUE)
循环队列(Circular queue, CIRCLEQ)
SLIST:单向无尾队列。SLIST 非常适合具有大数据集且很少或没有删除的应用程序,或者用于实现 LIFO 后进先出队列。
STAILQ:单向有尾队列,节点 n 为尾节点。
LIST:双向无尾队列。
TAILQ:双向有尾队列。
CIRCLEQ:双向循环队列。
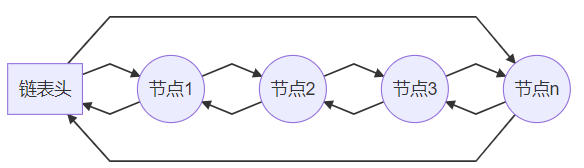
有尾、无尾的区别:通过这几张图可以发现,有尾(无尾)就是 head 头结构中有(无)指向链表尾节点的指针。
各种结构指向图
单向无尾队列 SLIST
SLIST:单向无尾队列。SLIST 非常适合具有大数据集且很少或没有删除的应用程序,或者用于实现 LIFO 后进先出队列。
扩展后的数据结构
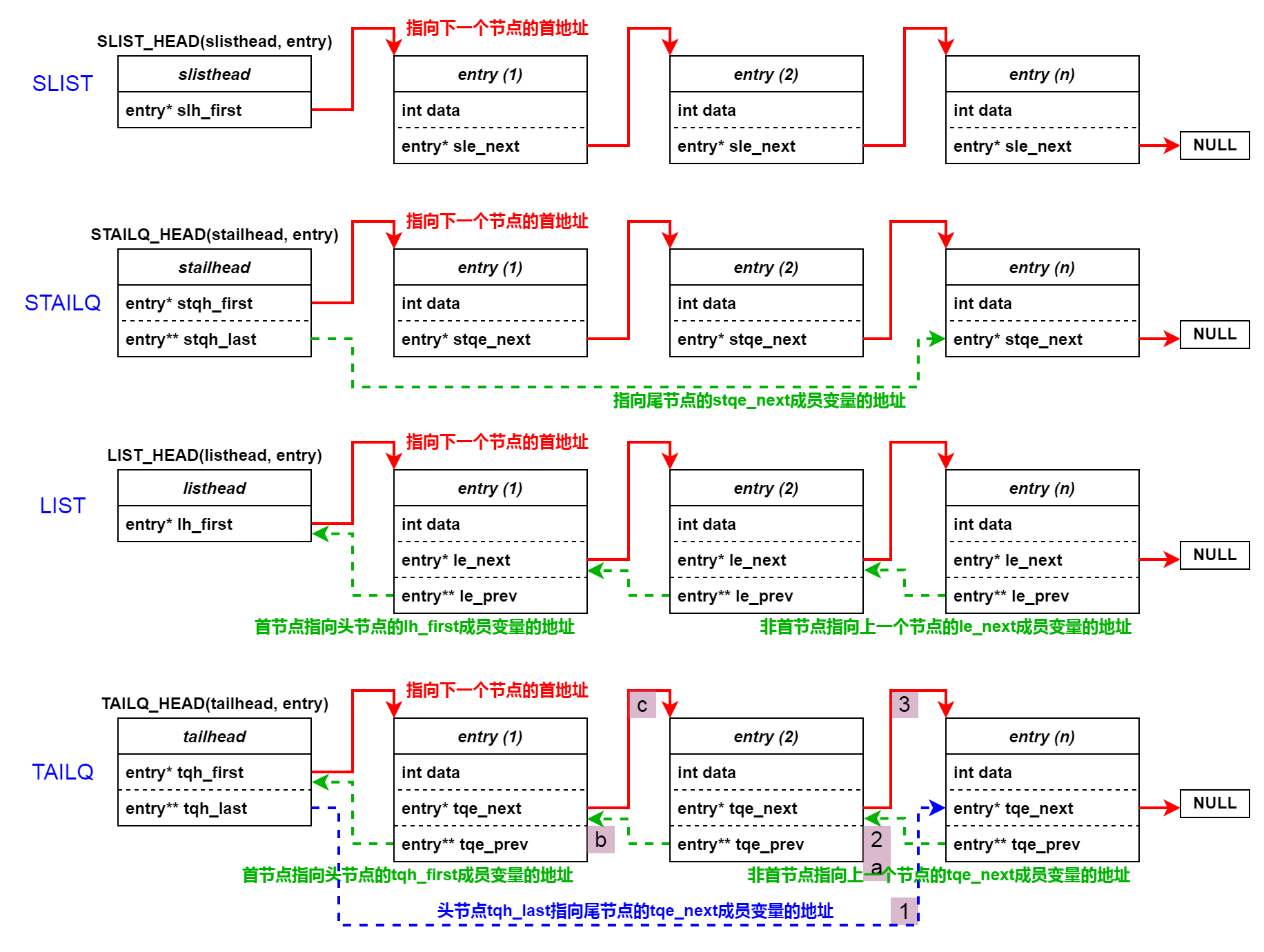
SLIST 数据结构涉及 SLIST_HEAD 和 SLIST_ENTRY 两个宏定义,先给出扩展后的数据结构示例,可以看出两处宏的 type 参数要保持统一(这里都是 entry)。
1 2 3 4 5 6 7 8 9 10 11 12 struct entry { int data; struct { struct entry * sle_next ; } entries; }; struct slisthead { struct entry * slh_first ; };
数据结构宏定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #define SLIST_HEAD(name, type) \ struct name { \ struct type* slh_first; \ } #define SLIST_HEAD_INITIALIZER(head) \ { NULL } #define SLIST_ENTRY(type) \ struct { \ struct type* sle_next; \ }
操作函数宏定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #define SLIST_INIT(head) \ do { \ (head)->slh_first = NULL; \ } while ( 0) #define SLIST_INSERT_AFTER(slistelm, elm, field) \ do { \ (elm)->field.sle_next = (slistelm)->field.sle_next; \ (slistelm)->field.sle_next = (elm); \ } while ( 0) #define SLIST_INSERT_HEAD(head, elm, field) \ do { \ (elm)->field.sle_next = (head)->slh_first; \ (head)->slh_first = (elm); \ } while ( 0) #define SLIST_REMOVE_HEAD(head, field) \ do { \ (head)->slh_first = (head)->slh_first->field.sle_next; \ } while ( 0) #define SLIST_REMOVE(head, elm, type, field) \ do { \ if ((head)->slh_first == (elm)) { \ SLIST_REMOVE_HEAD((head), field); \ } else { \ struct type* curelm = (head)->slh_first; \ while (curelm->field.sle_next != (elm)) \ curelm = curelm->field.sle_next; \ curelm->field.sle_next = curelm->field.sle_next->field.sle_next; \ } \ } while ( 0) #define SLIST_FOREACH(var, head, field) for ((var) = (head)->slh_first; (var); (var) = (var)->field.sle_next)
访问宏定义
1 2 3 4 5 6 #define SLIST_EMPTY(head) ((head)->slh_first == NULL) #define SLIST_FIRST(head) ((head)->slh_first) #define SLIST_NEXT(elm, field) ((elm)->field.sle_next)
示例代码
示例代码来自:man-pages
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <stddef.h> #include <stdio.h> #include <stdlib.h> #include <sys/queue.h> struct entry { int data; SLIST_ENTRY(entry) entries; }; SLIST_HEAD(slisthead, entry); int main (void ) { struct entry *n1 , *n2 , *n3 , *np ; struct slisthead head ; SLIST_INIT(&head); n1 = malloc (sizeof (struct entry)); SLIST_INSERT_HEAD(&head, n1, entries); n2 = malloc (sizeof (struct entry)); SLIST_INSERT_AFTER(n1, n2, entries); SLIST_REMOVE(&head, n2, entry, entries); free (n2); n3 = SLIST_FIRST(&head); SLIST_REMOVE_HEAD(&head, entries); free (n3); for (unsigned int i = 0 ; i < 5 ; i++) { n1 = malloc (sizeof (struct entry)); SLIST_INSERT_HEAD(&head, n1, entries); n1->data = i; } SLIST_FOREACH(np, &head, entries) { printf ("%i " , np->data); } printf ("\r\n" ); while (!SLIST_EMPTY(&head)) { n1 = SLIST_FIRST(&head); SLIST_REMOVE_HEAD(&head, entries); free (n1); } SLIST_INIT(&head); exit (EXIT_SUCCESS); }
单向有尾队列 STAILQ
STAILQ:单向有尾队列,节点 n 为尾节点。
扩展后的数据结构
STAILQ 数据结构涉及 STAILQ_HEAD 和 STAILQ_ENTRY 两个宏定义,先给出扩展后的数据结构示例,可以看出两处宏的 type 参数要保持统一(这里都是 entry)。
1 2 3 4 5 6 7 8 9 10 11 12 13 struct entry { int data; struct { struct entry * stqe_next ; } entries; }; struct stailhead { struct entry * stqh_first ; struct entry ** stqh_last ; };
数据结构宏定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #define STAILQ_HEAD(name, type) \ struct name { \ struct type* stqh_first; \ struct type** stqh_last; \ } #define STAILQ_HEAD_INITIALIZER(head) \ { NULL, &(head).stqh_first } #define STAILQ_ENTRY(type) \ struct { \ struct type* stqe_next; \ }
操作函数宏定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #define STAILQ_INIT(head) \ do { \ (head)->stqh_first = NULL; \ (head)->stqh_last = &(head)->stqh_first; \ } while ( 0) #define STAILQ_INSERT_HEAD(head, elm, field) \ do { \ if (((elm)->field.stqe_next = (head)->stqh_first) == NULL) \ (head)->stqh_last = &(elm)->field.stqe_next; \ (head)->stqh_first = (elm); \ } while ( 0) #define STAILQ_INSERT_TAIL(head, elm, field) \ do { \ (elm)->field.stqe_next = NULL; \ *(head)->stqh_last = (elm); \ (head)->stqh_last = &(elm)->field.stqe_next; \ } while ( 0) #define STAILQ_INSERT_AFTER(head, listelm, elm, field) \ do { \ if (((elm)->field.stqe_next = (listelm)->field.stqe_next) == NULL) \ (head)->stqh_last = &(elm)->field.stqe_next; \ (listelm)->field.stqe_next = (elm); \ } while ( 0) #define STAILQ_REMOVE_HEAD(head, field) \ do { \ if (((head)->stqh_first = (head)->stqh_first->field.stqe_next) == NULL) \ (head)->stqh_last = &(head)->stqh_first; \ } while ( 0) #define STAILQ_REMOVE(head, elm, type, field) \ do { \ if ((head)->stqh_first == (elm)) { \ STAILQ_REMOVE_HEAD((head), field); \ } else { \ struct type* curelm = (head)->stqh_first; \ while (curelm->field.stqe_next != (elm)) \ curelm = curelm->field.stqe_next; \ if ((curelm->field.stqe_next = curelm->field.stqe_next->field.stqe_next) == NULL) \ (head)->stqh_last = &(curelm)->field.stqe_next; \ } \ } while ( 0) #define STAILQ_FOREACH(var, head, field) for ((var) = ((head)->stqh_first); (var); (var) = ((var)->field.stqe_next)) #define STAILQ_CONCAT(head1, head2) \ do { \ if (!STAILQ_EMPTY((head2))) { \ *(head1)->stqh_last = (head2)->stqh_first; \ (head1)->stqh_last = (head2)->stqh_last; \ STAILQ_INIT((head2)); \ } \ } while ( 0)
访问宏定义
1 2 3 4 5 6 #define STAILQ_EMPTY(head) ((head)->stqh_first == NULL) #define STAILQ_FIRST(head) ((head)->stqh_first) #define STAILQ_NEXT(elm, field) ((elm)->field.stqe_next)
示例代码
示例代码来自:man-pages
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include <stddef.h> #include <stdio.h> #include <stdlib.h> #include <sys/queue.h> struct entry { int data; STAILQ_ENTRY(entry) entries; }; STAILQ_HEAD(stailhead, entry); int main (void ) { struct entry *n1 , *n2 , *n3 , *np ; struct stailhead head ; STAILQ_INIT(&head); n1 = malloc (sizeof (struct entry)); STAILQ_INSERT_HEAD(&head, n1, entries); n1 = malloc (sizeof (struct entry)); STAILQ_INSERT_TAIL(&head, n1, entries); n2 = malloc (sizeof (struct entry)); STAILQ_INSERT_AFTER(&head, n1, n2, entries); STAILQ_REMOVE(&head, n2, entry, entries); free (n2); n3 = STAILQ_FIRST(&head); STAILQ_REMOVE_HEAD(&head, entries); free (n3); n1 = STAILQ_FIRST(&head); n1->data = 0 ; for (unsigned int i = 1 ; i < 5 ; i++) { n1 = malloc (sizeof (struct entry)); STAILQ_INSERT_HEAD(&head, n1, entries); n1->data = i; } STAILQ_FOREACH(np, &head, entries) { printf ("%i " , np->data); } printf ("\r\n" ); n1 = STAILQ_FIRST(&head); while (n1 != NULL ) { n2 = STAILQ_NEXT(n1, entries); free (n1); n1 = n2; } STAILQ_INIT(&head); exit (EXIT_SUCCESS); }
双向无尾队列 LIST
LIST:双向无尾队列。
扩展后的数据结构
LIST 数据结构涉及 LIST_HEAD 和 LIST_ENTRY 两个宏定义,先给出扩展后的数据结构示例,可以看出两处宏的 type 参数要保持统一(这里都是 entry)。
1 2 3 4 5 6 7 8 9 10 11 12 13 struct entry { int data; struct { struct entry * le_next ; struct entry ** le_prev ; } entries; }; struct listhead { struct entry * lh_first ; }
数据结构宏定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #define LIST_HEAD(name, type) \ struct name { \ struct type* lh_first; \ } #define LIST_HEAD_INITIALIZER(head) \ { NULL } #define LIST_ENTRY(type) \ struct { \ struct type* le_next; \ struct type** le_prev; \ }
操作函数宏定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #define LIST_INIT(head) \ do { \ (head)->lh_first = NULL; \ } while ( 0) #define LIST_INSERT_AFTER(listelm, elm, field) \ do { \ if (((elm)->field.le_next = (listelm)->field.le_next) != NULL) \ (listelm)->field.le_next->field.le_prev = &(elm)->field.le_next; \ (listelm)->field.le_next = (elm); \ (elm)->field.le_prev = &(listelm)->field.le_next; \ } while ( 0) #define LIST_INSERT_BEFORE(listelm, elm, field) \ do { \ (elm)->field.le_prev = (listelm)->field.le_prev; \ (elm)->field.le_next = (listelm); \ *(listelm)->field.le_prev = (elm); \ (listelm)->field.le_prev = &(elm)->field.le_next; \ } while ( 0) #define LIST_INSERT_HEAD(head, elm, field) \ do { \ if (((elm)->field.le_next = (head)->lh_first) != NULL) \ (head)->lh_first->field.le_prev = &(elm)->field.le_next; \ (head)->lh_first = (elm); \ (elm)->field.le_prev = &(head)->lh_first; \ } while ( 0) #define LIST_REMOVE(elm, field) \ do { \ if ((elm)->field.le_next != NULL) \ (elm)->field.le_next->field.le_prev = (elm)->field.le_prev; \ *(elm)->field.le_prev = (elm)->field.le_next; \ } while ( 0) #define LIST_FOREACH(var, head, field) for ((var) = ((head)->lh_first); (var); (var) = ((var)->field.le_next))
访问宏定义
1 2 3 4 5 6 #define LIST_EMPTY(head) ((head)->lh_first == NULL) #define LIST_FIRST(head) ((head)->lh_first) #define LIST_NEXT(elm, field) ((elm)->field.le_next)
示例代码
示例代码来自:man-pages
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <stddef.h> #include <stdio.h> #include <stdlib.h> #include <sys/queue.h> struct entry { int data; LIST_ENTRY(entry) entries; }; LIST_HEAD(listhead, entry); int main (void ) { struct entry *n1 , *n2 , *n3 , *np ; struct listhead head ; int i; LIST_INIT(&head); n1 = malloc (sizeof (struct entry)); LIST_INSERT_HEAD(&head, n1, entries); n2 = malloc (sizeof (struct entry)); LIST_INSERT_AFTER(n1, n2, entries); n3 = malloc (sizeof (struct entry)); LIST_INSERT_BEFORE(n2, n3, entries); i = 0 ; LIST_FOREACH(np, &head, entries) { np->data = i++; } LIST_REMOVE(n2, entries); free (n2); LIST_FOREACH(np, &head, entries) { printf ("%i " , np->data); } printf ("\r\n" ); n1 = LIST_FIRST(&head); while (n1 != NULL ) { n2 = LIST_NEXT(n1, entries); free (n1); n1 = n2; } LIST_INIT(&head); exit (EXIT_SUCCESS); }
双向有尾队列 TAILQ
TAILQ:双向有尾队列。
扩展后的数据结构
TAILQ 数据结构涉及 TAILQ_HEAD 和 TAILQ_ENTRY 两个宏定义,先给出扩展后的数据结构示例,可以看出两处宏的 type 参数要保持统一(这里都是 entry)。
1 2 3 4 5 6 7 8 9 10 11 12 struct entry { int data; struct { struct entry * tqe_next ; struct entry ** tqe_prev ; } entries; }; struct tailhead { struct entry * tqh_first ; struct entry ** tqh_last ; };
tqe_prev和 tqh_last 为什么是二级指针,换成一级指针行不行?
肯定不行,如果它的前面是头节点怎么办,头节点的定义里面没有 struct entry 结构体类型啊!再仔细看看,不管是头节点还是普通节点,都有 struct entry* 结构体指针类型,那就定义一个类型为 struct entry** 的变量好了。这样前插的时候就可以统一处理了,例子见 TAILQ_INSERT_BEFORE。
数据结构宏定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #define _TAILQ_HEAD(name, type, qual) \ struct name { \ qual type* tqh_first; \ qual type* qual* tqh_last; \ } #define TAILQ_HEAD(name, type) _TAILQ_HEAD(name, struct type,) #define TAILQ_HEAD_INITIALIZER(head) \ { NULL, &(head).tqh_first } #define _TAILQ_ENTRY(type, qual) \ struct { \ qual type* tqe_next; \ qual type* qual* tqe_prev; \ } #define TAILQ_ENTRY(type) _TAILQ_ENTRY(struct type,)
操作函数宏定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 #define TAILQ_INIT(head) \ do { \ (head)->tqh_first = NULL; \ (head)->tqh_last = &(head)->tqh_first; \ } while ( 0) #define TAILQ_INSERT_HEAD(head, elm, field) \ do { \ if (((elm)->field.tqe_next = (head)->tqh_first) != NULL) \ (head)->tqh_first->field.tqe_prev = &(elm)->field.tqe_next; \ else \ (head)->tqh_last = &(elm)->field.tqe_next; \ (head)->tqh_first = (elm); \ (elm)->field.tqe_prev = &(head)->tqh_first; \ } while ( 0) #define TAILQ_INSERT_TAIL(head, elm, field) \ do { \ (elm)->field.tqe_next = NULL; \ (elm)->field.tqe_prev = (head)->tqh_last; \ *(head)->tqh_last = (elm); \ (head)->tqh_last = &(elm)->field.tqe_next; \ } while ( 0) #define TAILQ_INSERT_AFTER(head, listelm, elm, field) \ do { \ if (((elm)->field.tqe_next = (listelm)->field.tqe_next) != NULL) \ (elm)->field.tqe_next->field.tqe_prev = &(elm)->field.tqe_next; \ else \ (head)->tqh_last = &(elm)->field.tqe_next; \ (listelm)->field.tqe_next = (elm); \ (elm)->field.tqe_prev = &(listelm)->field.tqe_next; \ } while ( 0) #define TAILQ_INSERT_BEFORE(listelm, elm, field) \ do { \ (elm)->field.tqe_prev = (listelm)->field.tqe_prev; \ (elm)->field.tqe_next = (listelm); \ *(listelm)->field.tqe_prev = (elm); \ (listelm)->field.tqe_prev = &(elm)->field.tqe_next; \ } while ( 0) #define TAILQ_REMOVE(head, elm, field) \ do { \ if (((elm)->field.tqe_next) != NULL) \ (elm)->field.tqe_next->field.tqe_prev = (elm)->field.tqe_prev; \ else \ (head)->tqh_last = (elm)->field.tqe_prev; \ *(elm)->field.tqe_prev = (elm)->field.tqe_next; \ } while ( 0) #define TAILQ_FOREACH(var, head, field) for ((var) = ((head)->tqh_first); (var); (var) = ((var)->field.tqe_next)) #define TAILQ_FOREACH_REVERSE(var, head, headname, field) for ((var) = (*(((struct headname*)((head)->tqh_last))->tqh_last)); (var); (var) = (*(((struct headname*)((var)->field.tqe_prev))->tqh_last))) #define TAILQ_CONCAT(head1, head2, field) \ do { \ if (!TAILQ_EMPTY(head2)) { \ *(head1)->tqh_last = (head2)->tqh_first; \ (head2)->tqh_first->field.tqe_prev = (head1)->tqh_last; \ (head1)->tqh_last = (head2)->tqh_last; \ TAILQ_INIT((head2)); \ } \ } while ( 0)
访问宏定义
1 2 3 4 5 6 7 8 9 #define TAILQ_EMPTY(head) ((head)->tqh_first == NULL) #define TAILQ_FIRST(head) ((head)->tqh_first) #define TAILQ_NEXT(elm, field) ((elm)->field.tqe_next) #define TAILQ_LAST(head, headname) (*(((struct headname*)((head)->tqh_last))->tqh_last)) #define TAILQ_PREV(elm, headname, field) (*(((struct headname*)((elm)->field.tqe_prev))->tqh_last))
TAILQ_LAST
TAILQ_LAST 可以获取尾节点的结构体首地址(不是尾节点的 tqe_next 成员地址),它是如何获取到的?
(head)->tqh_last 是最后一个节点的 entries.tqe_next 成员的地址,可是这个地址不是用户想要的,用户要的是节点的地址(结构体的首地址),所以只好曲线救国,请看《各种结构指向图》小节的 TAILQ,从 1 到 2 再到 3。
从 entries.tqe_next 的地址怎么得到 entries.tqe_prev 的值呢(目的是为了得到倒数第二个节点的 entries.tqe_next)?
其实也不难,虽然 struct entry 里面 entries 这个结构体变量没有标签,但是 它的元素构成和 struct headname 完全一样 ,都是一个 struct entry* 和一个 struct entry**,所以可以把 entries.tqe_next 的地址强制转换为 (struct headname *) 类型:
(struct headname *)((head)->tqh_last)
然后访问它的 tqh_last 成员(也就是图中尾节点的 tqe_prev):
((struct headname *)((head)->tqh_last))->tqh_last
这样就得到了前一个节点的 entries.tqe_next 的地址,再对它解引用:
*(((struct headname *)((head)->tqh_last))->tqh_last)
就得到了 entries.tqe_next 变量,这恰好是大结构体( struct entry )的首地址。
TAILQ_PREV
我们再看 TAILQ_PREV 这个宏,道理类似。请看《各种结构指向图》小节的 TAILQ,从 a 到 b 再到 c。
设当前节点的地址是 elm(图中用最后这个节点来示意),(elm)->field.tqe_prev,表示顺着 a,得到它前面那个节点的 tqe_next 成员的地址,对这个地址强制转换为 struct headname *,即
(struct headname *)((elm)->field.tqe_prev)
再通过访问 tqh_last(等效于访问 tqe_prev),也就是顺着 b,得到了 elm 前面的前面的节点的 tqe_next 地址,即
((struct headname *)((elm)->field.tqe_prev))->tqh_last
对它解引用,就得到 elm 前面的前面的节点的 tqe_next,它刚好是 c 指向的 elm前面的结构体的首地址。
*(((struct headname *)((elm)->field.tqe_prev))->tqh_last)
示例代码
示例代码来自:man-pages
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include <stddef.h> #include <stdio.h> #include <stdlib.h> #include <sys/queue.h> struct entry { int data; TAILQ_ENTRY(entry) entries; }; TAILQ_HEAD(tailhead, entry); int main (void ) { struct entry *n1 , *n2 , *n3 , *np ; struct tailhead head ; int i; TAILQ_INIT(&head); n1 = malloc (sizeof (struct entry)); n1->data = 20 ; TAILQ_INSERT_HEAD(&head, n1, entries); n1 = malloc (sizeof (struct entry)); n1->data = 30 ; TAILQ_INSERT_TAIL(&head, n1, entries); n2 = malloc (sizeof (struct entry)); n2->data = 40 ; TAILQ_INSERT_AFTER(&head, n1, n2, entries); n3 = malloc (sizeof (struct entry)); n3->data = 50 ; TAILQ_INSERT_BEFORE(n2, n3, entries); TAILQ_REMOVE(&head, n2, entries); free (n2); i = 0 ; TAILQ_FOREACH(np, &head, entries) { np->data = np->data + (i++); } TAILQ_FOREACH_REVERSE(np, &head, tailhead, entries) { printf ("%i " , np->data); } printf ("\r\n" ); n1 = TAILQ_FIRST(&head); while (n1 != NULL ) { n2 = TAILQ_NEXT(n1, entries); free (n1); n1 = n2; } TAILQ_INIT(&head); exit (EXIT_SUCCESS); }
参考资料
https://www.cnblogs.com/fuzidage/p/14482501.html https://blog.csdn.net/ET_Endeavoring/article/details/121609082 SLIT: https://blog.csdn.net/longintchar/article/details/122907350
STAILQ: https://blog.csdn.net/longintchar/article/details/122907478
TAILQ: https://blog.csdn.net/longintchar/article/details/122907708