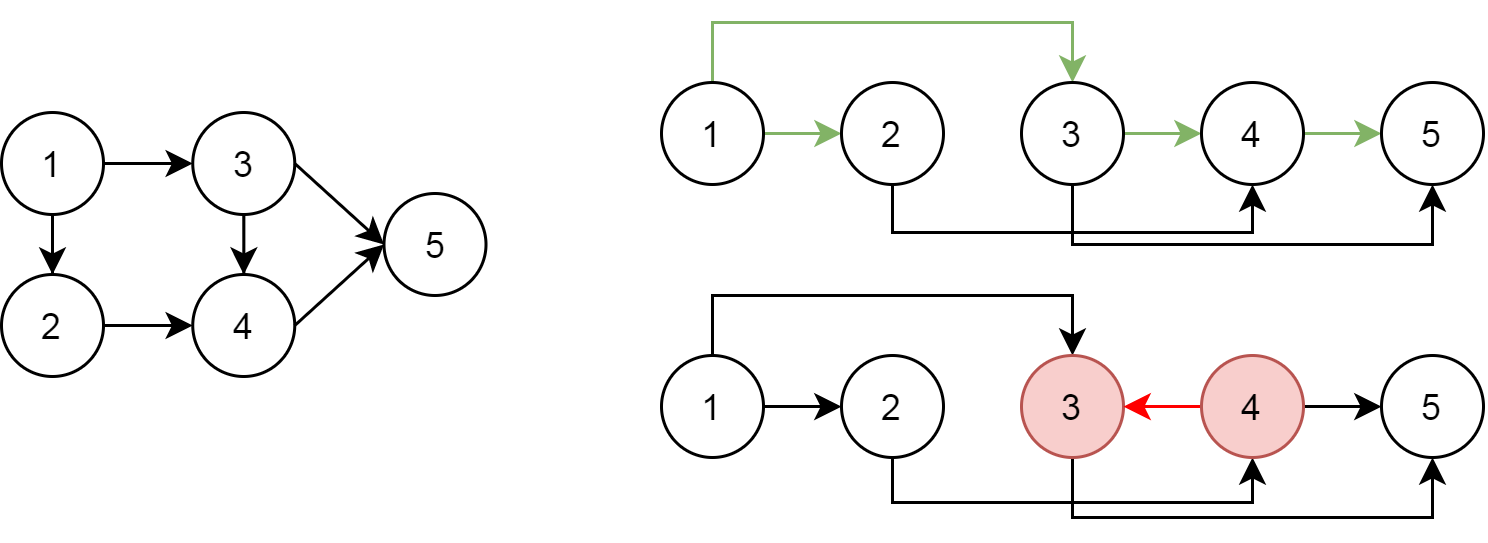
对一个有向无环图(Directed Acyclic Graph, DAG)G 进行拓扑排序,是将 G 中所有顶点排成一个 线性序列 ,使得图中任意一对顶点 u 和 v,若边 <u,v>∈E(G),则 u 在线性序列中出现在 v 之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称 拓扑序列。
拓扑排序可以被理解为对一个有向无环图进行排序的操作。在这个排序中,图中的顶点被排列成一个线性序列,满足以下条件:对于图中的任意一对顶点 u 和 v,如果存在一条边 <u,v>,那么在线性序列中,顶点 u 出现在顶点 v 之前。
// Define the structure for a node in the queue typedefstructNode { ELEM_TYPE data; structNode* next; } Node;
// Define the structure for the queue typedefstructQueue { int size; Node* front; Node* rear; } Queue;
// Function to create a new node Node* createNode(ELEM_TYPE data) { Node* newNode = (Node *)malloc(sizeof(Node)); newNode->data = data; newNode->next = NULL; return newNode; }
// Function to create an empty queue Queue* createQueue() { Queue* queue = (Queue *)malloc(sizeof(Queue)); queue->front = NULL; queue->rear = NULL; queue->size = 0; returnqueue; }
// Function to check if the queue is empty boolisEmpty(Queue* queue) { returnqueue->size == 0; }
// Function to enqueue an element into the queue voidenQueue(Queue* queue, ELEM_TYPE data) { Node* newNode = createNode(data); if (isEmpty(queue)) { queue->front = queue->rear = newNode; } else { queue->rear->next = newNode; queue->rear = newNode; } queue->size += 1; }
// Function to dequeue an element from the queue ELEM_TYPE deQueue(Queue* queue) { if (isEmpty(queue)) { return-1; } Node* temp = queue->front; ELEM_TYPE data = temp->data; queue->front = queue->front->next; queue->size -= 1; free(temp); return data; }
int* findOrder(int numCourses, int** prerequisites, int prerequisitesSize, int* prerequisitesColSize, int* returnSize) { int indegree[numCourses]; // 每个节点的入度,入度为 0 表示不受其它节点影响 int **edges = (int **)malloc(numCourses * sizeof(int *)); // 二维数组, 记录每个节点影响的节点们 int edgeNums[numCourses]; // 记录每个节点影响的节点数量, 用于动态扩展空间 int *ans = (int *)malloc(numCourses * sizeof(int)); // 初始化 for (int i = 0; i < numCourses; ++i) { indegree[i] = 0; edgeNums[i] = 0; edges[i] = (int *)malloc(0 * sizeof(int)); // 后续按需扩展 } // 遍历所有节点对 for (int i = 0; i < prerequisitesSize; ++i) { int suff = prerequisites[i][0], pre = prerequisites[i][1]; edgeNums[pre]++; // suff 受到了 pre 影响, 故 pre 节点影响的节点数量 +1 indegree[suff]++; // suff 受到了 pre 影响,其入度要 +1 edges[pre] = (int *)realloc(edges[pre], edgeNums[pre] * sizeof(int)); // 扩展内存 edges[pre][edgeNums[pre] - 1] = suff; // 在索引(pre, 最后位置) 记录 suff }
Queue* queue = createQueue(); // 入度所有不受影响的节点 for(int i = 0; i < numCourses; ++i) { if (indegree[i] == 0) { enQueue(queue, i); } } int count = 0; while (!isEmpty(queue)) { ELEM_TYPE cur = deQueue(queue); ans[count++] = cur;
// 遍历出队的节点影响的所有节点, 它们的受影响度将 -1 for (int i = 0; i < edgeNums[cur]; ++i) { int x = edges[cur][i]; indegree[x]--; if (indegree[x] == 0) { enQueue(queue, x); } } }
for (int i = 0; i < numCourses; ++i) { free(edges[i]); } free(edges); // 判断结果队列长度,确定是否可以完成拓扑排序 if (count == numCourses) { (*returnSize) = count; } else { (*returnSize) = 0; } return ans; }