/** * An RTE ring structure. * * The producer and the consumer have a head and a tail index. The particularity * of these index is that they are not between 0 and size(ring). These indexes * are between 0 and 2^32, and we mask their value when we access the ring[] * field. Thanks to this assumption, we can do subtractions between 2 index * values in a modulo-32bit base: that's why the overflow of the indexes is not * a problem. */ structrte_ring { char name[RTE_RING_NAMESIZE]; /**< Name of the ring. */ int flags; /**< 创建模式,支持多 / 单生产者和多 / 单消费者 */ conststructrte_memzone* memzone; /**< Memzone, if any, containing the rte_ring */ /**< rte_menzone 是 dpdk 内存管理底层的数据结构,memzone 用于记录在哪块 mem 分配的 rte_ring,释放的时候使用 */
/** Ring producer status. 生产者数据结构 */ structprod { uint32_t watermark; /**< Maximum items before EDQUOT. 水位线,用于检查入队后是否超过水位线 */ uint32_t sp_enqueue; /**< True, if single producer. */ uint32_t size; /**< Size of ring. */ uint32_t mask; /**< Mask (size-1) of ring. */ volatileuint32_t head; /**< Producer head. 入队前更新 head 字段,然后进行入队 */ volatileuint32_t tail; /**< Producer tail. 入队完更新 tail 字段(让先更新过 head 字段的线程 优先更新 tail 字段,自己等待一会),更新后 tail == head */ } prod __rte_cache_aligned;
/** Ring consumer status. 消费者数据结构 */ structcons { uint32_t sc_dequeue; /**< True, if single consumer. */ uint32_t size; /**< Size of the ring. */ uint32_t mask; /**< Mask (size-1) of ring. */ volatileuint32_t head; /**< Consumer head. 与生产者处理逻辑一样 */ volatileuint32_t tail; /**< Consumer tail. 与生产者处理逻辑一样 */ #ifdef RTE_RING_SPLIT_PROD_CONS /* 这个属性就是要求 gcc 在编译的时候,把 cons/prod 结构分配到不同的 cache line,为什么这样做? 因为如果没有这些的话,这两个结构在内存上是连续的,编译器不会把他们分配到不同 cache line, 而一般上这两个结构是要被不同的 CPU 核访问的,如果连续的话这两个核就会产生伪共享问题 */ } cons __rte_cache_aligned; #else } cons; #endif
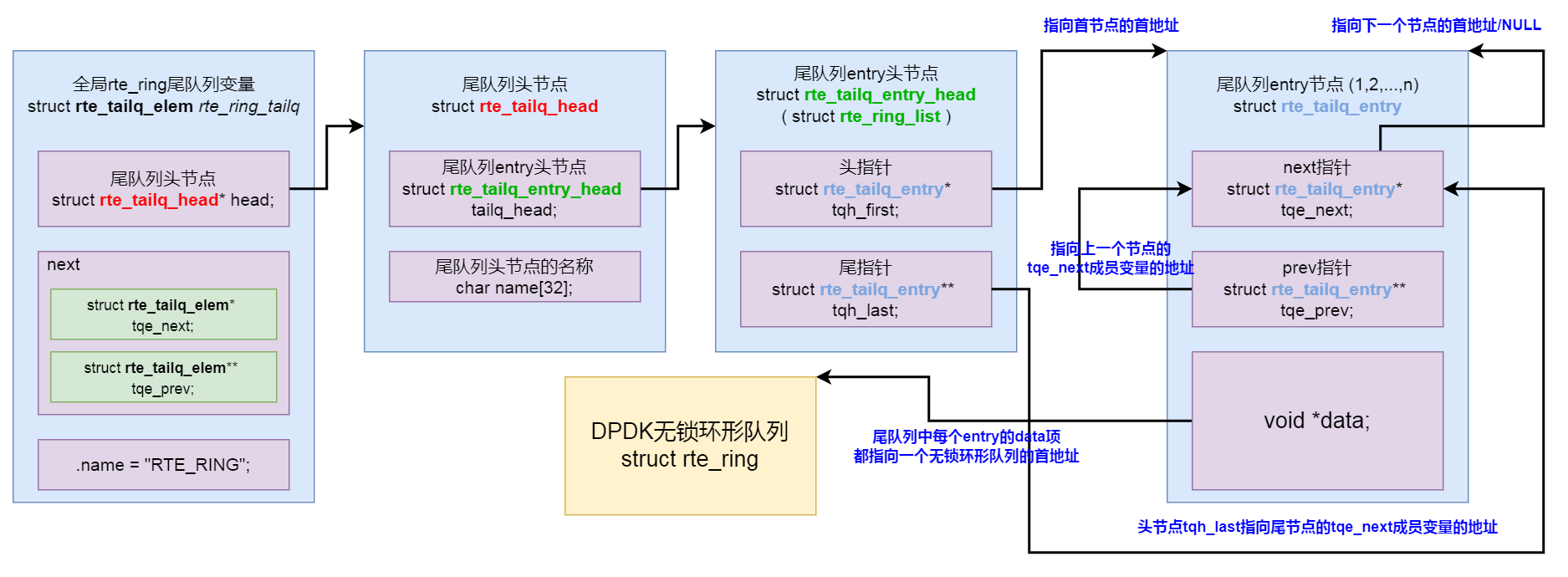
/* 尾队列表头 TAILQ_HEAD 宏定义 */ #define TAILQ_HEAD(name, type) \ struct name { \ struct type* tqh_first; /* first element */ \ struct type** tqh_last; /* addr of last next element */ \ }
/* 尾队列实体 TAILQ_ENTRY 宏定义 */ #define TAILQ_ENTRY(type) \ struct { \ struct type* tqe_next; /* next element */ \ struct type** tqe_prev; /* address of previous next element */ \ }
/** dummy structure type used by the rte_tailq APIs */ structrte_tailq_entry { /* 扩展到: struct { struct rte_tailq_entry* tqe_next; struct rte_tailq_entry** tqe_prev; } next; */ TAILQ_ENTRY(rte_tailq_entry) next; /**< Pointer entries for a tailq list */ void* data; /**< Pointer to the data referenced by this tailq entry */ };
/** * The structure defining a tailq header entry for storing * in the rte_config structure in shared memory. Each tailq * is identified by name. * Any library storing a set of objects e.g. rings, mempools, hash-tables, * is recommended to use an entry here, so as to make it easy for * a multi-process app to find already-created elements in shared memory. */ structrte_tailq_head { structrte_tailq_entry_headtailq_head;/**< NOTE: must be first element */ char name[RTE_TAILQ_NAMESIZE]; };
structrte_tailq_elem { /** * Reference to head in shared mem, updated at init time by * rte_eal_tailqs_init() * 在初始化时由 rte_eal_tailqs_init() 更新的共享内存中的头部引用 */ structrte_tailq_head* head; /* 扩展到: struct { struct rte_tailq_elem* tqe_next; struct rte_tailq_elem** tqe_prev; } next; */ TAILQ_ENTRY(rte_tailq_elem) next; constchar name[RTE_TAILQ_NAMESIZE]; };
/** * Return the first tailq entry casted to the right struct. * 返回转换为正确结构的第一个 tailq 条目 */ #define RTE_TAILQ_CAST(tailq_entry, struct_name) (struct struct_name*)&(tailq_entry)->tailq_head
/* 给唯一标识 ring 的名字增加一个前缀 */ snprintf(mz_name, sizeof(mz_name), "%s%s", RTE_RING_MZ_PREFIX, name);
rte_rwlock_write_lock(RTE_EAL_TAILQ_RWLOCK);
/* reserve a memory zone for this ring. If we can't get rte_config or * we are secondary process, the memzone_reserve function will set * rte_errno for us appropriately - hence no check in this this function * 为新创建的 ring 分配内存空间 */ mz = rte_memzone_reserve(mz_name, ring_size, socket_id, mz_flags); if (mz != NULL) { r = mz->addr; // 获取分配的内存空间的起始地址 /* no need to check return value here, we already checked the * arguments above */ rte_ring_init(r, name, count, flags); // ring 队列初始化
/* free the ring */ voidrte_ring_free(struct rte_ring* r) { structrte_ring_list* ring_list =NULL; structrte_tailq_entry* te;
if (r == NULL) return;
/* * Ring was not created with rte_ring_create, * therefore, there is no memzone to free. */ if (r->memzone == NULL) { RTE_LOG(ERR, RING, "Cannot free ring (not created with rte_ring_create()"); return; }
/** * @internal Enqueue several objects on a ring (NOT multi-producers safe). * * @param r * A pointer to the ring structure. * @param obj_table * A pointer to a table of void * pointers (objects). * @param n * The number of objects to add in the ring from the obj_table. * @param behavior 环的两种入队模式:固定数量入队、尽力而为入队 * RTE_RING_QUEUE_FIXED: Enqueue a fixed number of items from a ring * RTE_RING_QUEUE_VARIABLE: Enqueue as many items a possible from ring * @return * Depend on the behavior value * if behavior = RTE_RING_QUEUE_FIXED * - 0: Success; objects enqueue. * - -EDQUOT: Quota exceeded. The objects have been enqueued, but the * high water mark is exceeded. * - -ENOBUFS: Not enough room in the ring to enqueue, no object is enqueued. * if behavior = RTE_RING_QUEUE_VARIABLE * - n: Actual number of objects enqueued. */ staticinlineint __attribute__((always_inline)) __rte_ring_sp_do_enqueue(struct rte_ring *r, void * const *obj_table, unsigned n, enum rte_ring_queue_behavior behavior) { uint32_t prod_head, cons_tail; // 假设无边界时,两指针的相对顺序:0____ct------ph________+inf uint32_t prod_next, free_entries; unsigned i; uint32_t mask = r->prod.mask; // 等于 size(ring)-1 int ret;
/* The subtraction is done between two unsigned 32bits value * (the result is always modulo 32 bits even if we have * prod_head > cons_tail). So 'free_entries' is always between 0 * and size(ring)-1. */ free_entries = mask + cons_tail - prod_head;
/* check that we have enough room in ring */ if (unlikely(n > free_entries)) { // 入队的 obj 数量大于队列空余空间 if (behavior == RTE_RING_QUEUE_FIXED) { // 固定数量入队模式:无法全部入队,异常退出 __RING_STAT_ADD(r, enq_fail, n); return -ENOBUFS; } else { // 尽力而为入队模式:入队全部空余空间,即入队 free_entries 个 obj /* No free entry available */ if (unlikely(free_entries == 0)) { __RING_STAT_ADD(r, enq_fail, n); return0; }
/** * @internal Dequeue several objects from a ring (NOT multi-consumers safe). * When the request objects are more than the available objects, only dequeue * the actual number of objects 当请求出队量大于队列剩余量,则仅出队实际余量 * * @param r * A pointer to the ring structure. * @param obj_table * A pointer to a table of void * pointers (objects) that will be filled. * 从 ring 中出队的 obj 存放到 obj_table 指向的内存里 * @param n * The number of objects to dequeue from the ring to the obj_table. * @param behavior 环的两种出队模式:固定数量出队、尽力而为出队 * RTE_RING_QUEUE_FIXED: Dequeue a fixed number of items from a ring * RTE_RING_QUEUE_VARIABLE: Dequeue as many items a possible from ring * @return * Depend on the behavior value * if behavior = RTE_RING_QUEUE_FIXED * - 0: Success; objects dequeued. * - -ENOENT: Not enough entries in the ring to dequeue; no object is * dequeued. 余量不足,则不出队任何 obj * if behavior = RTE_RING_QUEUE_VARIABLE * - n: Actual number of objects dequeued. */ staticinlineint __attribute__((always_inline)) __rte_ring_sc_do_dequeue(struct rte_ring *r, void **obj_table, unsigned n, enum rte_ring_queue_behavior behavior) { uint32_t cons_head, prod_tail; // 假设无边界时,两指针的相对顺序:0____ct------ph________+inf uint32_t cons_next, entries; unsigned i; uint32_t mask = r->prod.mask;
/* The subtraction is done between two unsigned 32bits value * (the result is always modulo 32 bits even if we have * cons_head > prod_tail). So 'entries' is always between 0 * and size(ring)-1. */ entries = prod_tail - cons_head; // ring 中的 obj 数量
/** * @internal Enqueue several objects on the ring (multi-producers safe). * * This function uses a "compare and set" instruction to move the * producer index atomically. * 该函数使用 CAS 指令,原子地修改生产者索引 * * @param r * A pointer to the ring structure. * @param obj_table * A pointer to a table of void * pointers (objects). * @param n * The number of objects to add in the ring from the obj_table. * @param behavior * RTE_RING_QUEUE_FIXED: Enqueue a fixed number of items from a ring * RTE_RING_QUEUE_VARIABLE: Enqueue as many items a possible from ring * @return * Depend on the behavior value * if behavior = RTE_RING_QUEUE_FIXED * - 0: Success; objects enqueue. * - -EDQUOT: Quota exceeded. The objects have been enqueued, but the * high water mark is exceeded. * - -ENOBUFS: Not enough room in the ring to enqueue, no object is enqueued. * if behavior = RTE_RING_QUEUE_VARIABLE * - n: Actual number of objects enqueued. */ staticinlineint __attribute__((always_inline)) __rte_ring_mp_do_enqueue(struct rte_ring *r, void * const *obj_table, unsigned n, enum rte_ring_queue_behavior behavior) { uint32_t prod_head, prod_next; // 假设无边界时,两指针的相对顺序:......____ct------ph________... uint32_t cons_tail, free_entries; constunsigned max = n; int success; unsigned i, rep = 0; uint32_t mask = r->prod.mask; int ret;
/* Avoid the unnecessary cmpset operation below, which is also * potentially harmful when n equals 0. */ if (n == 0) return0;
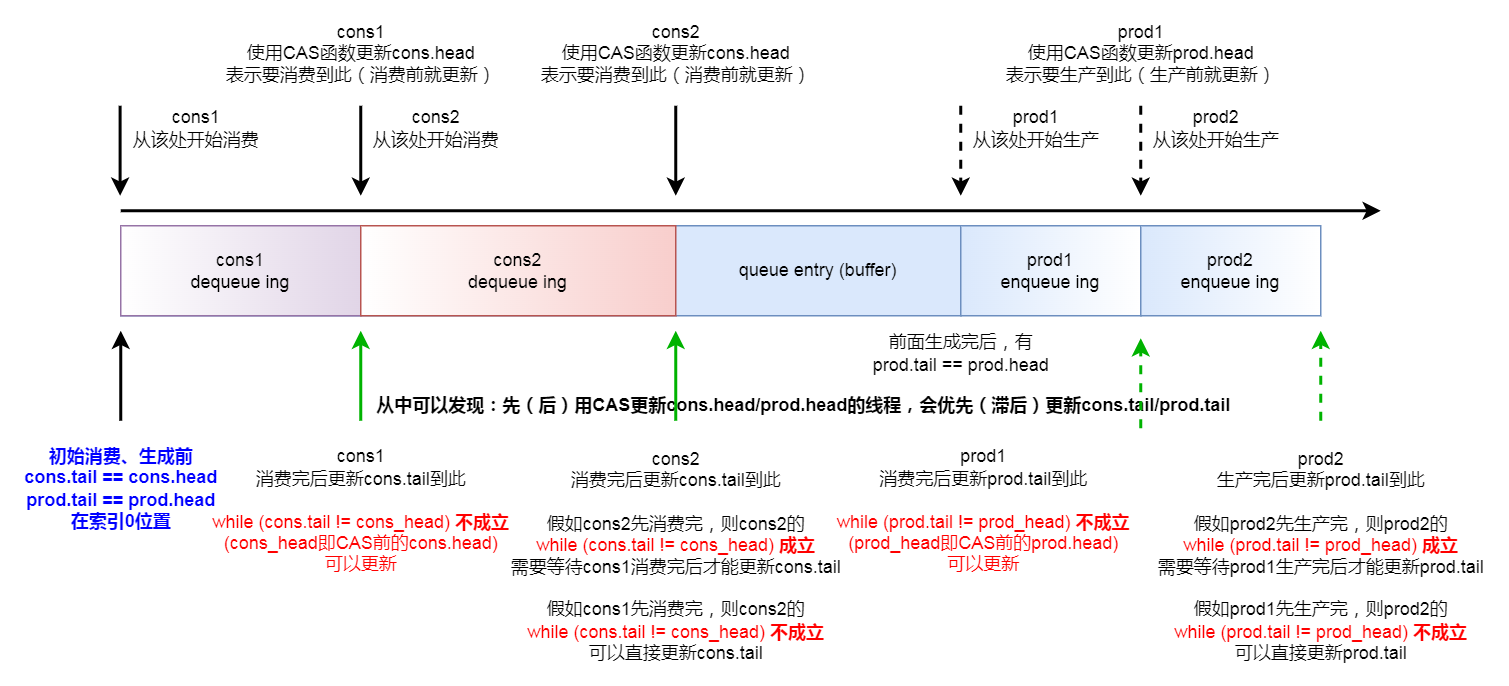
/* move prod.head atomically */ do { /* Reset n to the initial burst count */ n = max;
/* * while (unlikely(success == 0)) 时,说明有其他线程修改了 r->prod.head, * 因此,这里要重新读取,并执行 CAS 指令,否则永远不会 success == 1 退出 */ prod_head = r->prod.head; cons_tail = r->cons.tail; /* The subtraction is done between two unsigned 32bits value * (the result is always modulo 32 bits even if we have * prod_head > cons_tail). So 'free_entries' is always between 0 * and size(ring)-1. */ free_entries = (mask + cons_tail - prod_head);
/* check that we have enough room in ring */ if (unlikely(n > free_entries)) { // 入队的 obj 数量大于队列空余空间 if (behavior == RTE_RING_QUEUE_FIXED) { // 固定数量入队模式:无法全部入队,异常退出 __RING_STAT_ADD(r, enq_fail, n); return -ENOBUFS; } else { // 尽力而为入队模式:入队全部空余空间,即入队 free_entries 个 obj /* No free entry available */ if (unlikely(free_entries == 0)) { __RING_STAT_ADD(r, enq_fail, n); return0; }
/* write entries in ring */ ENQUEUE_PTRS(); // 入队操作(与单生产者入队操作执行过程一样) rte_smp_wmb(); // 内存屏蔽
/* if we exceed the watermark */ if (unlikely(((mask + 1) - free_entries + n) > r->prod.watermark)) { // 已经用的空间 + 本次实际使用的空间 大于 水位线 ret = (behavior == RTE_RING_QUEUE_FIXED) ? -EDQUOT : (int)(n | RTE_RING_QUOT_EXCEED); // 按模式指定异常返回值 __RING_STAT_ADD(r, enq_quota, n); } else { ret = (behavior == RTE_RING_QUEUE_FIXED) ? 0 : n; // 返回对应模式的成功状态下的返回值 __RING_STAT_ADD(r, enq_success, n); }
/* * If there are other enqueues in progress that preceded us, * we need to wait for them to complete * 如果在我们之前,还有其他更早的生产者线程正在入队, * 我们需要等待他们完成,然后再更新 prod.tail */ while (unlikely(r->prod.tail != prod_head)) { rte_pause();
/* Set RTE_RING_PAUSE_REP_COUNT to avoid spin too long waiting * for other thread finish. It gives pre-empted thread a chance * to proceed and finish with ring dequeue operation. */ if (RTE_RING_PAUSE_REP_COUNT && ++rep == RTE_RING_PAUSE_REP_COUNT) { rep = 0; sched_yield(); } } r->prod.tail = prod_next; // 修改 ring 结构中的 prod.tail 指针(mp 模式下,这里等于 CAS 更新后的 r->prod.head 的值) return ret; }
CAS 函数源码
x86 平台的实现:lib\librte_eal\common\include\arch\x86\rte_atomic.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
/*------------------------- 32 bit atomic operations -------------------------*/
/** * @internal Dequeue several objects from a ring (multi-consumers safe). When * the request objects are more than the available objects, only dequeue the * actual number of objects * * This function uses a "compare and set" instruction to move the * consumer index atomically. * * @param r * A pointer to the ring structure. * @param obj_table * A pointer to a table of void * pointers (objects) that will be filled. * @param n * The number of objects to dequeue from the ring to the obj_table. * @param behavior * RTE_RING_QUEUE_FIXED: Dequeue a fixed number of items from a ring * RTE_RING_QUEUE_VARIABLE: Dequeue as many items a possible from ring * @return * Depend on the behavior value * if behavior = RTE_RING_QUEUE_FIXED * - 0: Success; objects dequeued. * - -ENOENT: Not enough entries in the ring to dequeue; no object is * dequeued. * if behavior = RTE_RING_QUEUE_VARIABLE * - n: Actual number of objects dequeued. */
staticinlineint __attribute__((always_inline)) __rte_ring_mc_do_dequeue(struct rte_ring *r, void **obj_table, unsigned n, enum rte_ring_queue_behavior behavior) { uint32_t cons_head, prod_tail; // 假设无边界时,两指针的相对顺序:......____ch------pt________... uint32_t cons_next, entries; constunsigned max = n; int success; unsigned i, rep = 0; uint32_t mask = r->prod.mask;
/* Avoid the unnecessary cmpset operation below, which is also * potentially harmful when n equals 0. */ if (n == 0) return0;
/* move cons.head atomically */ do { /* Restore n as it may change every loop */ n = max;
cons_head = r->cons.head; prod_tail = r->prod.tail; /* The subtraction is done between two unsigned 32bits value * (the result is always modulo 32 bits even if we have * cons_head > prod_tail). So 'entries' is always between 0 * and size(ring)-1. */ entries = (prod_tail - cons_head);
/* Set the actual entries for dequeue */ if (n > entries) { if (behavior == RTE_RING_QUEUE_FIXED) { __RING_STAT_ADD(r, deq_fail, n); return -ENOENT; } else { if (unlikely(entries == 0)){ __RING_STAT_ADD(r, deq_fail, n); return0; }
/* copy in table */ DEQUEUE_PTRS(); rte_smp_rmb();
/* * If there are other dequeues in progress that preceded us, * we need to wait for them to complete */ while (unlikely(r->cons.tail != cons_head)) { rte_pause();
/* Set RTE_RING_PAUSE_REP_COUNT to avoid spin too long waiting * for other thread finish. It gives pre-empted thread a chance * to proceed and finish with ring dequeue operation. */ if (RTE_RING_PAUSE_REP_COUNT && ++rep == RTE_RING_PAUSE_REP_COUNT) { rep = 0; sched_yield(); } } __RING_STAT_ADD(r, deq_success, n); r->cons.tail = cons_next;