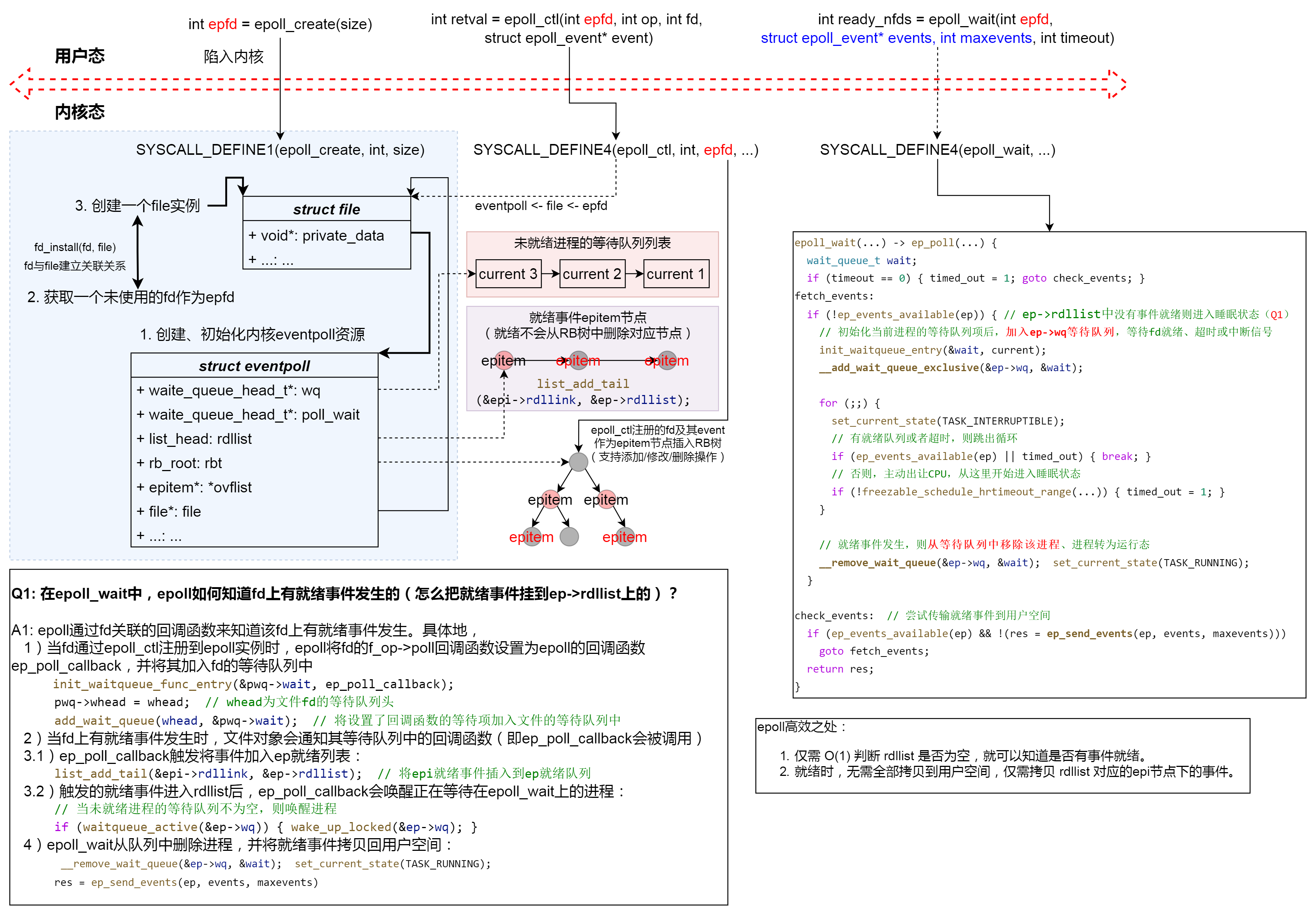
intepoll_create(int size); intepoll_ctl(int epfd, int op, int fd, struct epoll_event* event); intepoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout);
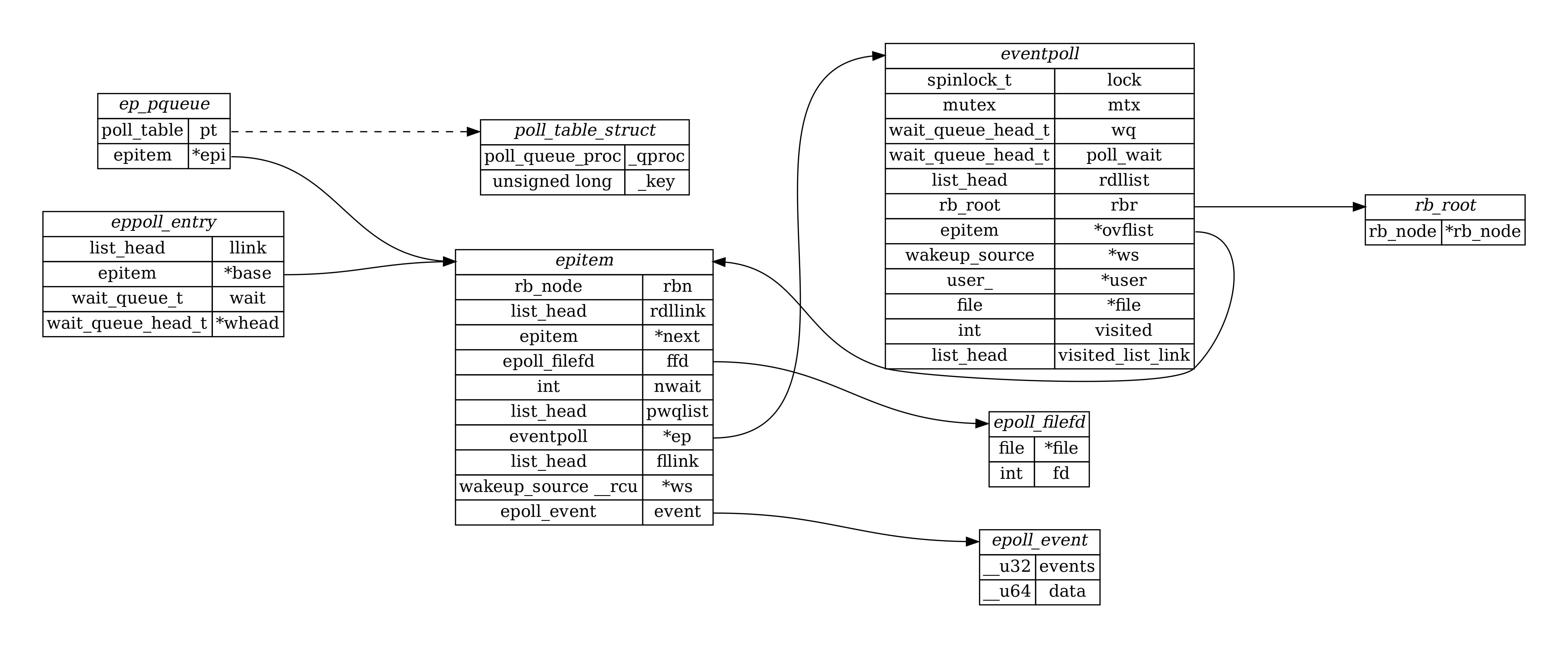
/* * This structure is stored inside the "private_data" member of the file ⭐ * structure and represents the main data structure for the eventpoll * interface. */ structeventpoll { /* Protect the access to this structure */ spinlock_t lock;
/* * This mutex is used to ensure that files are not removed * while epoll is using them. This is held during the event * collection loop, the file cleanup path, the epoll file exit * code and the ctl operations. */ structmutexmtx;
/* Wait queue used by sys_epoll_wait() */ wait_queue_head_t wq; // <- 将即将阻塞的进程加入到这个等待队列里 ⭐ // <- 后续 fd 事件触发时,会唤醒这个列表
/* Wait queue used by file->poll() */ wait_queue_head_t poll_wait;
/* * This is a single linked list that chains all the "struct epitem" that * happened while transferring ready events to userspace w/out * holding ->lock. */ structepitem* ovflist;// <- ep->ovflist = epi in the func "ep_poll_callback"
/* wakeup_source used when ep_scan_ready_list is running */ structwakeup_source* ws;
/* The user that created the eventpoll descriptor */ structuser_struct* user;
structfile* file;// <- ep 对应的的文件地址 ⭐
/* used to optimize loop detection check */ int visited; structlist_headvisited_list_link; };
/* <- epoll_ctl 的 op=EPOLL_CTL_ADD 时,会往红黑树中插入一个 epitem 节点 * Each file descriptor added to the eventpoll interface will * have an entry of this type linked to the "rbr" RB tree. */ structepitem { /* RB tree node used to link this structure to the eventpoll RB tree */ structrb_noderbn;// <- 放在首位,可以用于从红黑树中找到节点后,强转得到 epitem 结构
/* List header used to link this structure to the eventpoll ready list */ structlist_headrdllink;// <- 事件就绪时,将其链接到 ep->rdllist 列表下 ⭐
/* * Works together "struct eventpoll"->ovflist in keeping the * single linked chain of items. */ structepitem* next;// <- epi->next = ep->ovflist in the func "ep_poll_callback"
/* The file descriptor information this item refers to */ structepoll_filefdffd;// <- 这个节点所属的 eventpoll 文件,ffd.fd 就是 epfd 吧 ⭐
/* Number of active wait queue attached to poll operations */ int nwait;
/* List containing poll wait queues */ structlist_headpwqlist;
/* The "container" of this item */ structeventpoll* ep;// <- 这个节点所属的 eventpoll 的地址 ⭐
/* List header used to link this item to the "struct file" items list */ structlist_headfllink;
/* wakeup_source used when EPOLLWAKEUP is set */ structwakeup_source __rcu* ws;
/* The structure that describe the interested events and the source fd */ structepoll_eventevent;// <- 从用户态 epool_ctl 拷贝过来的用户关心的事件 ⭐ };
/* * This is the callback that is passed to the wait queue wakeup * mechanism. It is called by the stored file descriptors when they * have events to report. */ staticintep_poll_callback(wait_queue_t* wait, unsigned mode, int sync, void* key) { int pwake = 0; unsignedlong flags; structepitem* epi = ep_item_from_wait(wait); // 从 eppoll_entry 中获取 epi structeventpoll* ep = epi->ep; // 从 epi 中获取 ep
/* If this file is already in the ready list we exit soon */ if (!ep_is_linked(&epi->rdllink)) { // 将 epi 就绪事件插入到 ep 就绪队列 ⭐ list_add_tail(&epi->rdllink, &ep->rdllist); ep_pm_stay_awake_rcu(epi); }
// 如果活跃(有进程在等待),唤醒调用 epoll_wait() 而阻塞的进程 ⭐ if (waitqueue_active(&ep->wq)) wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait)) pwake++;
out_unlock: spin_unlock_irqrestore(&ep->lock, flags); if (pwake) ep_poll_safewake(&ep->poll_wait);
epi->event.events = event->events; /* need barrier below */ epi->event.data = event->data; /* protected by mtx */ if (epi->event.events & EPOLLWAKEUP) { if (!ep_has_wakeup_source(epi)) ep_create_wakeup_source(epi); } elseif (ep_has_wakeup_source(epi)) { ep_destroy_wakeup_source(epi); }
smp_mb();
revents = ep_item_poll(epi, &pt);
if (revents & event->events) { spin_lock_irq(&ep->lock); if (!ep_is_linked(&epi->rdllink)) { list_add_tail(&epi->rdllink, &ep->rdllist); ep_pm_stay_awake(epi);
/* Notify waiting tasks that events are available */ if (waitqueue_active(&ep->wq)) wake_up_locked(&ep->wq); if (waitqueue_active(&ep->poll_wait)) pwake++; } spin_unlock_irq(&ep->lock); }
/* We have to call this outside the lock */ if (pwake) ep_poll_safewake(&ep->poll_wait);