
操作系统之 chapter4.1 非连续内存分配之分段与分页 介绍了非连续内存的分段与分页技术。那么,如何才能有效的实现逻辑地址到物理地址的转换机制呢?那就是通过页表。本文将介绍页表、快表 TLB、二级 & 多级页表和反向页表,你将学习到如何进行地址转换,以及如何进一步高效的进行地址转换。
页表
页表概述
页表是操作系统中用于管理虚拟内存和物理内存之间 映射关系 的数据结构。它记录了虚拟地址和物理地址之间的对应关系,使得程序可以使用虚拟地址来访问物理内存,而无需关注具体的物理内存地址。
每一个运行的程序都有一个独立的页表:
- 页表属于程序运行状态,会动态变化
- PTBR(Page Table Base Register):页表基址寄存器,用于存储页表的基地址,以指示当前使用的页表位置。
页表结构
页表其实就是一个大数组,它的索引 index 指的是 page-number(页号),索引对应的内容是 frame−number(帧号)。得到帧号后,再叠加上 offset(页帧内偏移)即可得到物理地址。
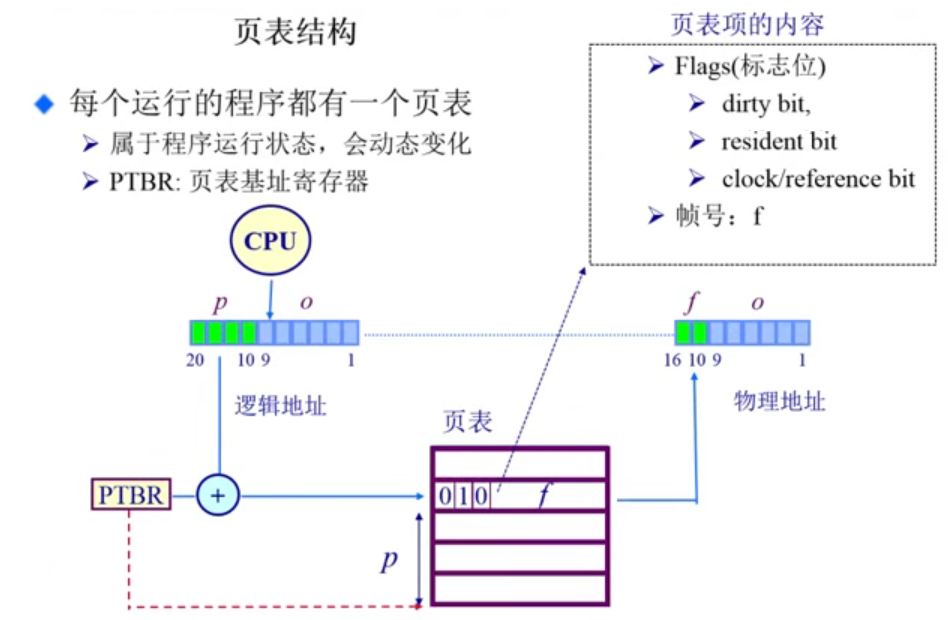
页表中还有一些特殊标志位:
- dirty bit,脏位
- resident bit,表示这个页表项是否合法(对应的物理地址中是否存在),0- 不存在,1- 存在
- clock/reference bit,时钟 / 参考位
上图中 PTBR 的作用?
当程序访问虚拟内存时,CPU 会将虚拟地址发送给内存管理单元(MMU),MMU 根据页表进行地址转换。在这个过程中,CPU 会读取 PTBR 寄存器中的值,以确定当前使用的页表的位置。通过 将虚拟地址的高位(即虚拟页号部分)与页表基地址相加,CPU 可以找到相应的表项,并进行地址转换,获取虚拟地址对应的物理地址。
PTBR 的值通常在操作系统进行上下文切换时被修改,以切换不同的页表。这样,不同的进程可以拥有独立的页表,实现虚拟内存的隔离和保护。通过修改 PTBR,操作系统可以控制不同进程之间的地址空间映射关系,从而实现多进程共享物理内存的管理。
地址转换实例
具有 16 位地址的系统,具有:
- 每页 1024 bytes,占用 10 位;帧号占用 6 位
- 物理内存大小为 2^6 * 1024 bytes = 64KB (图中应是 64KB)
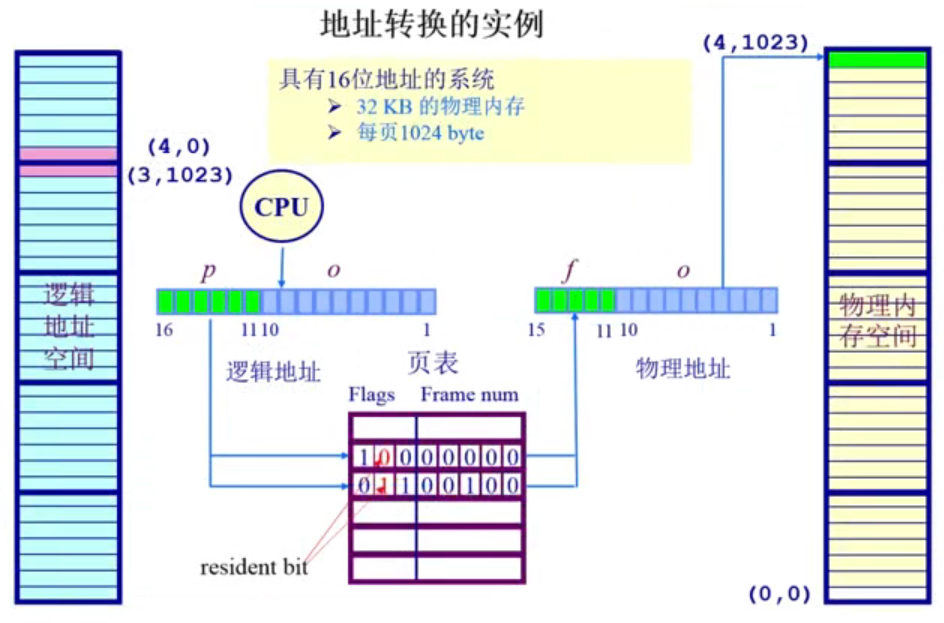
从图中可以了解到:
-
对于二元组为
(4, 0)的逻辑地址空间,它在页表中对应index = 4的那个页表项。可以看出,它对应的 resident bit 位的值为 0,表明这个页表项对应的物理地址不存在。这时请求访问物理内存,可能会造成 内存访问异常(可能要杀死程序)。 -
对于二元组为
(3, 1023)的逻辑地址空间,它在页表中对应index = 3的那个页表项。可以看出,它对应的 resident bit 位的值为 1,表明这个页表项对应的物理地址存在,对应的页帧号的二进制表示为00100,则对应的物理内存地址为(4, 1023),即 4x1024+1023=5119。
分页机制的性能问题
进程访问一次内存单元,需要 2 次内存访问:
- 一次用于获取页表项(通过页号查表获取页帧号)。
- 一次用于访问数据(访问物理内存的数据)。
页表可能非常大:
- 64 位的机器,如果每页 1024 字节,那么一个页表的大小是多少(有多少个页号)?
- ,这么大的页表,在内存中是放不下的。
- 每一个运行的程序都需要有一个页表。
如何处理?
- 缓存(Caching):使用 CPU 内部的 TLB(使用相关存储器,可以进行并发的、高速的查询)。
- 间接(Indirection)访问:使用二级页表、多级页表。
快表(TLB)——解决时间问题
转换后备缓冲区(Translation Look-aside Buffer, TLB)是一种高速缓存,也叫快表,用于加快虚拟地址到物理地址的转换过程 。它是页表的一部分, 用于存储最近使用的虚拟页与物理页的映射关系,以减少对页表的访问次数,提高地址转换的效率。
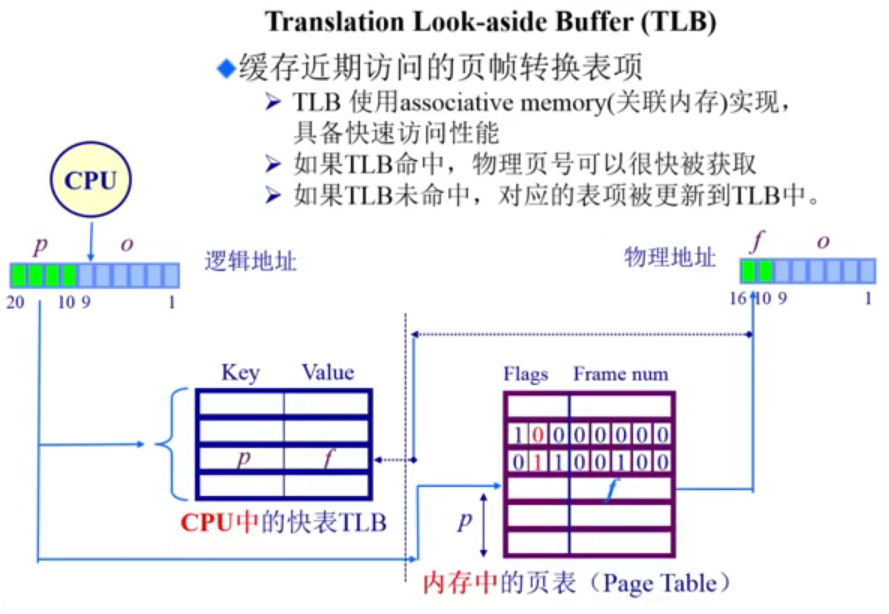
TLB 缓存近期访问的页帧转换表项:
- TLB 是一个小而快速的硬件缓存,使用关联内存(associative memory)实现,具备快速访问性能。每个 TLB 条目包含一个虚拟页号(VPN)和对应的物理页号(PPN),以及一些其他用于管理的标志位,如访问权限、脏位等。
- 如果 TLB 命中,物理页号可以很快被获取。
- 如果 TLB 未命中、缺失(TLB miss),对应的表项被更新到 TLB 中(该动作在 x86 的 CPU 中由硬件实现,其他的可能是由操作系统实现)。
当程序访问一个虚拟地址时,CPU 首先在 TLB 中查找对应的虚拟页号。如果找到了匹配的 TLB 条目,就可以直接从 TLB 中获取对应的物理页帧号,然后进行内存访问,无需访问页表。这个过程称为 TLB 命中。
TLB 缺失会不会很频繁呢?
不会的。假如 32 位的系统,每页的大小为 4K 字节,如果该页的每一个地址都访问一次的话,需要 4K 次才会造成一次 TLB 缺失——因为从当前页首访问到当前页尾,下次访问时会是不同的逻辑页号,这个页号可能不在 TLB 表中。(这是假设情况,实际中 TLB 缺失的频率取决于许多因素,无法简单地通过每页的大小和访问次数来确定 TLB 缺失的频率)
二级 & 多级页表——解决空间问题
二级 & 多级页表利用时间换空间,来解决页表的空间问题。
二级页表:
- 将页号分为两个部分、页表分为两个,一级页号对应一级页表,二级页号对应二级页表;
- 一级页号查表获得在二级页表的起始地址,地址加上二级页号的值,在二级页表中获得帧号。
二级页表节约了一定的空间 —— 在一级页表中如果 resident bit=0,则在二级页表中 不存储 相关 index,而只有一张页表的话,这一些 index 都需要保留。
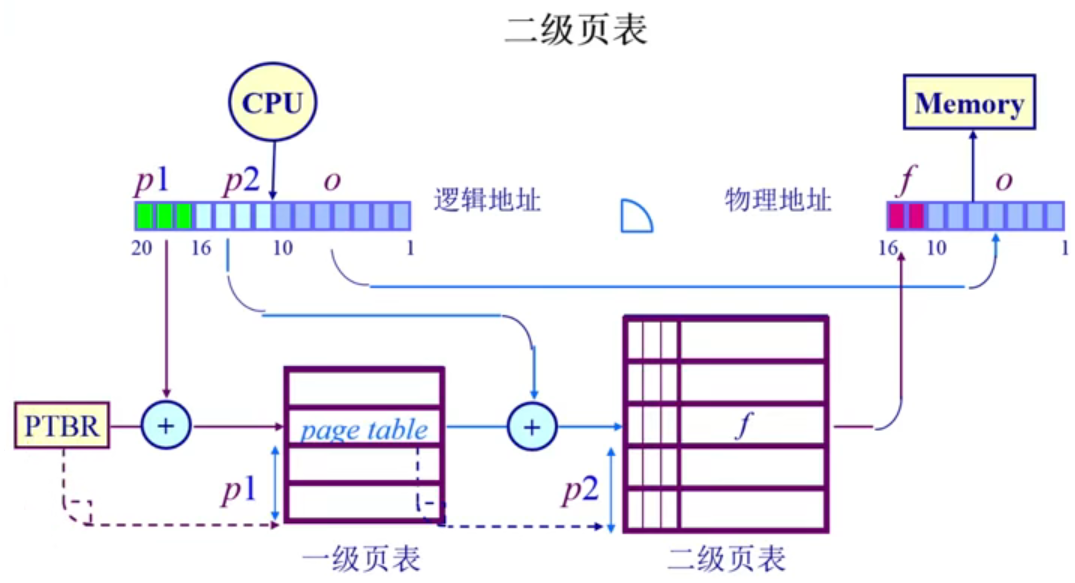
二级页表就像是目录的目录,先找到一级目录,再在一级目录内找到二级目录。
多级页表:
- 通过把页号分为
k个部分,来实现多级间接页表,建立一棵「页表树」。
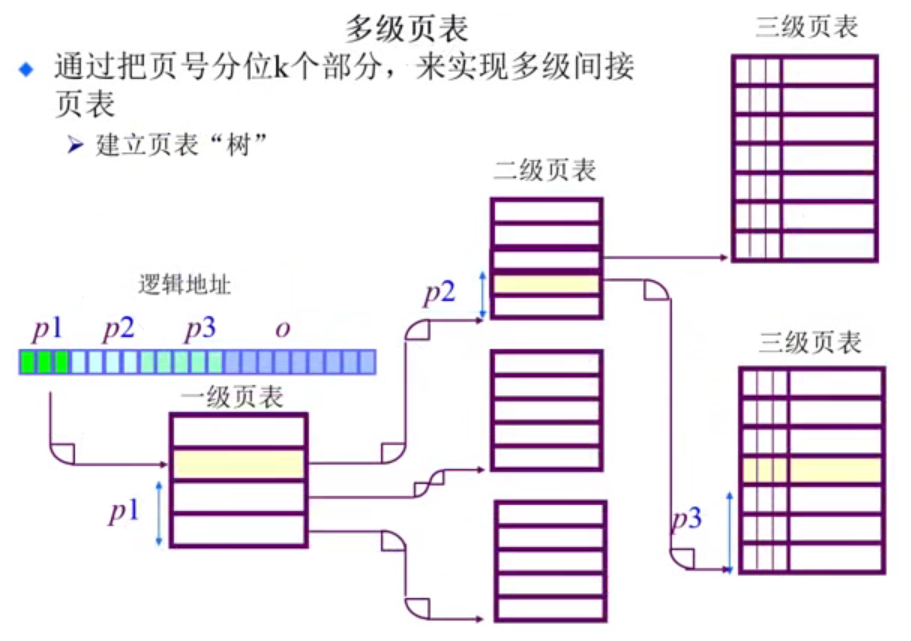
多级页表就像是目录的目录的目录…
反向页表
有没有一种方法使得页表的大小与逻辑地址大小没有那么大的关系,尽量与物理地址大小建立对应关系?——反向页表
什么是反向页表
在操作系统中,反向页表(Inverted Page Table)是一种用于虚拟内存管理的数据结构。与传统的页表不同,传统的页表将虚拟页号映射到物理页帧号,而反向页表将物理页帧号映射到虚拟页号。
反向页表的目的
反向页表的目的是 为了解决大型内存系统(地址的寻址空间非常大)中的页表大小太大(占用内存空间太大)和访问效率的问题。
传统页表和多级页表的弊端
传统页表:
在传统的页表中,每个进程都有自己的页表,而随着进程数量的增加和每个进程的逻辑地址空间的增大,页表的大小也会急剧增加。这样会导致内存开销大,并且访问页表的时间也会增加。
多级页表:
在大型内存系统(64-bits 系统)中,前向映射页表变得繁琐,比如:使用了 5 级页表。
反向页表的优势
在传统的页表中,每个进程都有自己的页表。而 反向页表只有一张,它只需要为系统中的每个物理页帧分配一个表项,每个表项记录了该物理页帧所属的进程号(PID)和虚拟页号 。当进行地址转换时, 操作系统只需通过物理页帧号查找反向页表,即可得到对应的进程号和虚拟页号。这样就避免了每个进程都拥有一个独立的页表,大大减少了页表的大小。
也就是,反向页表的大小只跟物理地址空间的大小相对应,而与快速增长的虚拟地址空间的大小无关。
操作系统只需通过物理页帧号查找反向页表,即可得到对应的进程号和虚拟页号:(个人理解)只要遍历查找的虚拟页号和进程号,跟当前的进程的 PID 和虚拟页号匹配上了,那么就可以使用这个物理页帧号来获取对应的物理内存,并访问数据了。
基于页寄存器(Page Registers)的方案
方案
页表中存储(页帧号,页号),使得页表大小与物理内存大小相关,而与逻辑内存关联减小。
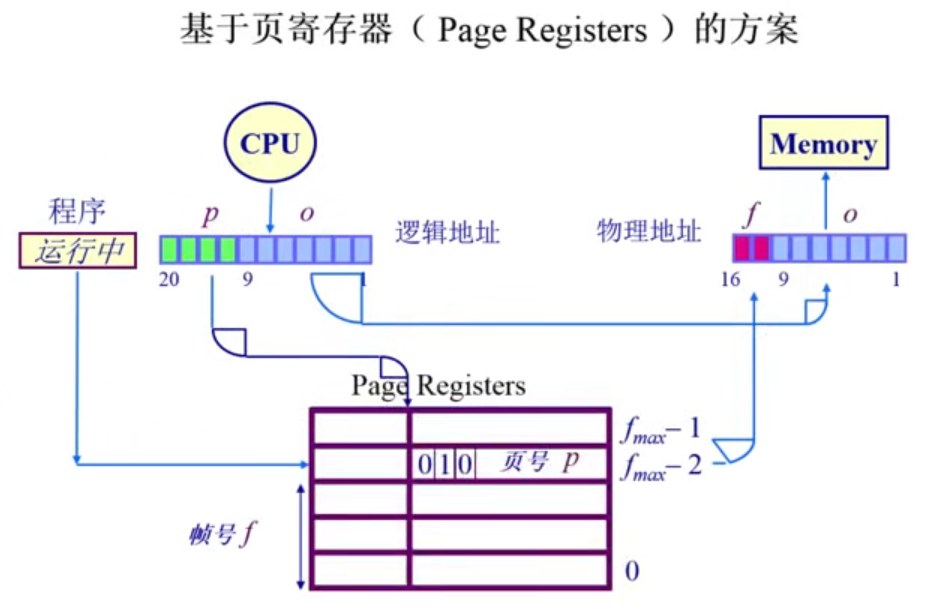
每一个页帧和一个页寄存器关联,寄存器内容包括:
- 使用位(resident bit):此帧是否被进程占用
- 占用页号(occupier):对应的页号 p
- 保护位(protection bits):保护位
页寄存器空间占比
有如下一个操作系统:
- 页面大小:4096 bytes = 4KB
- 页帧数:4096 = 4K
- 物理内存大小:4096 * 4096 bytes = 4K * 4KB = 16MB
则页寄存器使用的空间(假设 8 bytes/register):8 bytes * 4096 = 32KB
- 每一个页帧和一个页寄存器关联——页寄存器使用的空间即页表中所有页帧号对应页的页寄存器空间
- 页寄存器带来的额外内存开销占比:32KB / 16MB = 0.195%
- 虚拟内存大小:任意
优势
从上面的示例可以看出,基于页寄存器的方案有如下优势:
- 转换表的大小相对于物理内存来说很小
- 转换表的大小跟逻辑地址空间的大小无关
劣势
需要的信息对调了,即根据帧号可以找到页号。如何转换回来(如何根据页号找到页帧号)?
答:需要在反向页表中搜索想要的页号,才能得到对应的页帧号。
基于关联内存(associative memory)的方案
就是在前面 TLB 中提到的相关存储器,并发的、高速的查询,效率很快。
该方案在设计上,页表中存储(页帧号,页号),而不是像 TLB 中存储(页号,页帧号)。
劣势
硬件设计太复杂,容量不可能做大,需要放置在 CPU 中。
在反向页表中搜索一个页对应的页帧号:
- 如果帧数较少,页寄存器可以被放在关联内存中。
- 在关联内存中查找逻辑页号:
- 成功:页帧号被提取
- 失败:页错误异常(page fault)
- 限制因素,大量的关联存储非常昂贵
- 难以在单个时钟周期内完成
- 耗电
基于哈希(hash)的方案
基于哈希的方案可以有效缓解页帧号 - 页号的映射的开销,需要硬件帮助,但会出现哈希冲突。哈希冲突是指不同的页号可能映射到相同的页帧号,这会导致冲突和错误的映射。
方案
在基于哈希的反向页表中,为了解决哈希冲突,可以利用进程的 PID,在哈希函数的基础上再加一个 PID 参数,标记当前运行程序的编号,根据 hash(PID, p) 哈希函数,算出当前进程的页号所对应的页帧号。
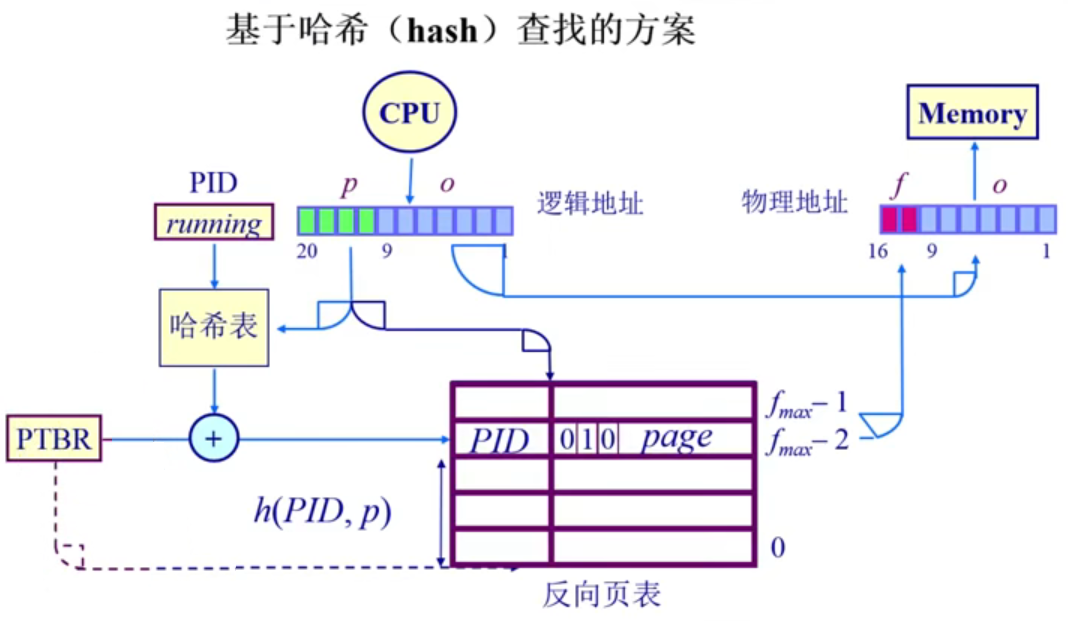
映射过程
基于哈希的反向页表解决哈希冲突示意图(图中 vpn 表示虚拟页号,ppn 表示物理页帧号):
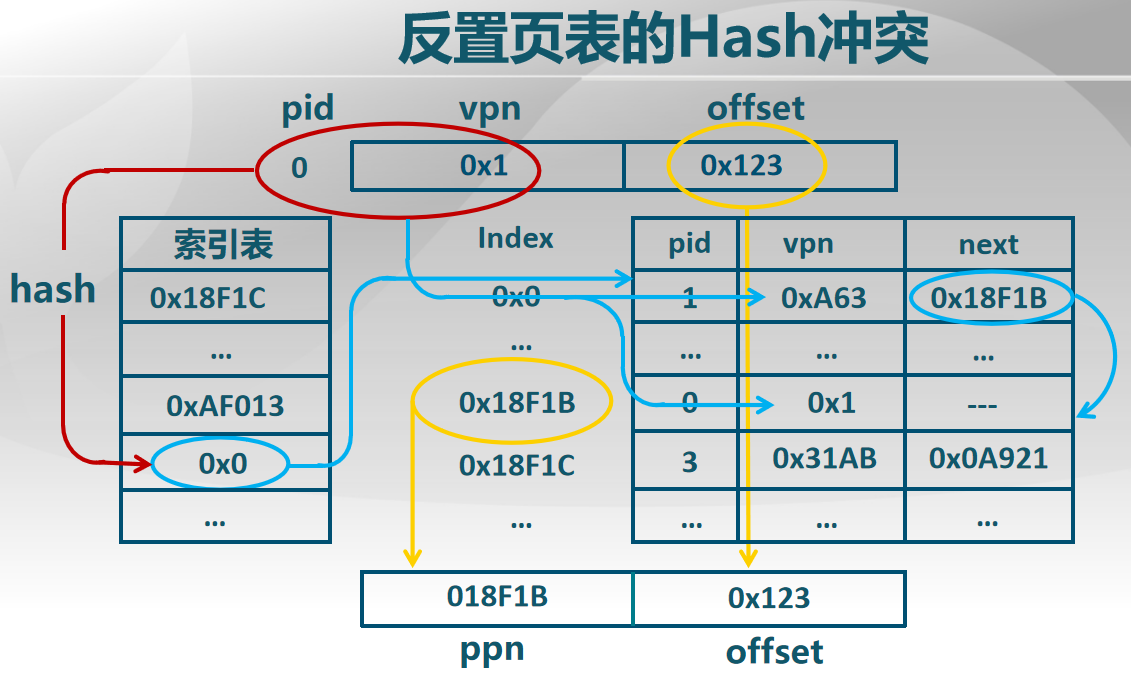
上图为基于哈希的反向页表解决哈希冲突,并搜索一个页对应的页帧号的过程,可以按照以下步骤进行:
-
对
PID和页号做哈希计算hash(PID, p),并使用它作为页寄存器表的索引,获取对应的页寄存器内容。- 如果寄存器表项中包含
p和PID,则搜索成功,索引号就是页帧号; - 如果寄存器表项中不包含
p和PID,说明存在哈希冲突。
- 如果寄存器表项中包含
-
如果存在哈希冲突:
- 在表项中寻找
next提供的页寄存器索引,通过该索引,重复步骤 1,直到寄存器表项中包含p和PID为止。
- 在表项中寻找
-
获取页帧号后,根据页帧号和页内偏移可以计算出虚拟地址映射的物理地址,并进行数据访问。
这样,即使存在哈希冲突,不同的进程会根据不同的
PID选择不同的页帧号,从而避免了冲突和错误的映射。
劣势
基于哈希的反向页表还是需要把反向页表放到内存中,做哈希计算时也需要到内存中取值。由于内存访问的时间开销较大,所以还需要有一个类似 TLB 的机制缓存起来,避免频繁地访问内存,提高寻址的效率。
优势
目前来说,这种机制只在高端 CPU 中存在,好处:
- 表的容量可以做的很小,只和物理空间关联
- 反向页表只有一张,它的大小只跟物理地址空间的大小相对应,所以它占的空间节省很多;但它是有代价的,它需要以一种很高速的哈希计算、硬件处理机制、高效函数以及解决冲突的机制才可以使访问的效率得到保障。这种机制由硬件、相应的操作系统软件配合,可以在空间和时间上取得比较好的结果。
参考资料:
1:https://github.com/OXygenMoon/OperatingSystemInDepth
2:https://blog.csdn.net/weixin_53407527/article/details/124891795